
Matura jako egzamin dojrzałości jest jednym z najważniejszych testów w życiu człowieka — zapewnia nam ona średnie wykształcenie i daje szanse na dobre studia i dobrze płatną pracę. Rozszerzone matury są również poświadczeniem naszej wiedzy z danej dziedziny, jednakże niektóre rozszerzenia nie należą do najłatwiejszych. Jednym z takich rozszerzeń jest informatyka, a ty zapewne znajdujesz się tu, aby poznać jej rozwiązania. Dobrze trafiłeś/aś — przedstawiamy arkusz matury z informatyki 2018 oraz jego rozwiązania z wytłumaczeniem.
Matura z informatyki 2018 — część pierwsza (teoria)
W części pierwszej matury z informatyki znajdziemy 3 zadania, z czego pierwsze i trzecie mają po 3 podpunkty, zaś drugie zadanie dwa podpunkty. Jak w prawie każdym egzaminie maturalnym, na samym końcu znajduje się również niepodlegający ocenie brudnopis. Należało oczywiście pamiętać o odpowiedniej organizacji czasu — na napisanie egzaminu było 60 minut. Przejdźmy zatem do rozwiązywania pierwszej części arkuszu matury z informatyki 2018.
Matura z informatyki 2018 odpowiedzi: Zadanie 1 — analiza
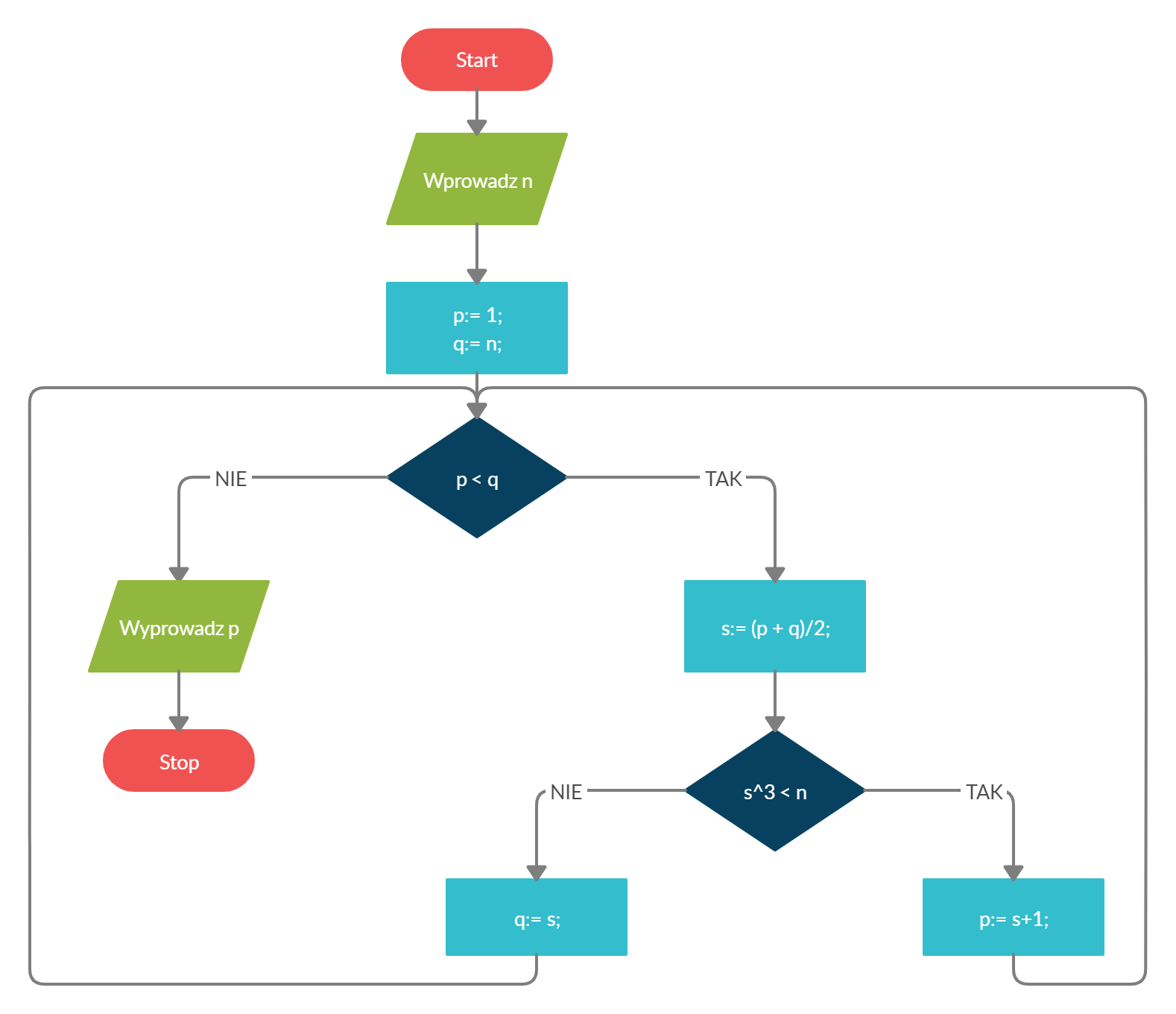
Zanim przejdziemy do rozwiązywania podpunktów proponuje przeanalizować podany w zadaniu algorytm:

- Użytkownik wprowadza liczbę n
- Program przypisuje dwie zmienne: p równą 1 i q = n (czyli przypisuje liczbę, którą wprowadził użytkownik)
- Następnie program rozpoczyna pętle typu while, z warunkiem p mniejsze od q:
- Przypisujemy zmienną s, która jest liczbą całkowitą, a jej wartość to średnia ze zmiennych p i q (a więc ich średnia „odrzuci” ułamek dziesiętny)
- Jeżeli sześcian liczby s jest mniejszy od liczby, którą wprowadził użytkownik, to liczba p przyjmie wartość s+1.
- W przeciwnym wypadku zmienna q przyjmie wartość zmiennej s.
- Zwróć wartość zmiennej p.
Schemat blokowy tego algorytmu w uproszczeniu wygląda tak:
Zadanie 1 — podpunkt 1
Jak go rozwiązać? „Ręcznie” sprawdzamy krok po kroku działanie algorytmu dla każdej liczby z tabeli, a następnie wpisujemy wartość zmiennej p. Rozwiązanie może być nieco czasochłonne i łatwo tu o pomyłkę, jednak nie powinno z nim być większego problemu. Rozwiązana tabela powinna wyglądać tak:
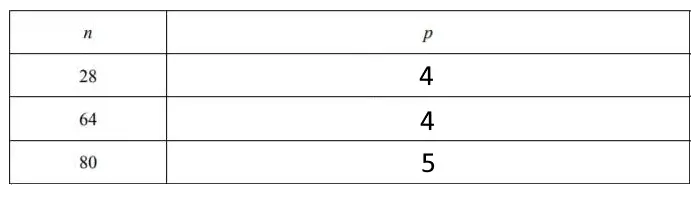
Zadanie 1 — podpunkt 2

Tutaj należy spojrzeć na to zadanie logicznie. Wynikiem końcowym musi być liczba 10. Taki wynik otrzymamy w sytuacji gdy:
- Zmienna s będzie równa 9 i jednocześnie jej sześcian będzie mniejszy od wprowadzonej liczby — wtedy algorytm zwiększy wartość p o 1, co da nam 10.
- Zmienna p będzie równa 10, a s również 10 — wtedy algorytm przerwie pracę, zwracając nam liczbę dziesięć.
Rozważając pierwszy przypadek powinniśmy otrzymać liczbę większą od 9*9*9, ale też jednocześnie jak najbliższą tej liczbie. 9 do 3 potęgi to 729, a najbliższa, większa liczba to 730. W kolejnym zaś przypadku wiedząc, że s=10 i nie spełnia warunku s^3 < n, to jedyną taką liczbą n, która nie spełnia tego warunku jest… 1000, gdyż jest to liczba równa, ale nie większa od sześcianu zmiennej s. Odpowiedziami są więc 730 i 1000.
Zadanie 1 — podpunkt 3

W tym zadaniu należy obliczyć złożoność obliczeniową algorytmu. Po dokładnej analizie problemu łatwo stwierdzić, iż jest to algorytm o złożoności liniowo—logarytmicznej, co zgadza się z odpowiedzią 2*log2(n). Rozwiązaniem jest więc odpowiedź A.
Matura z informatyki 2018 odpowiedzi: Zadanie 2 — programy
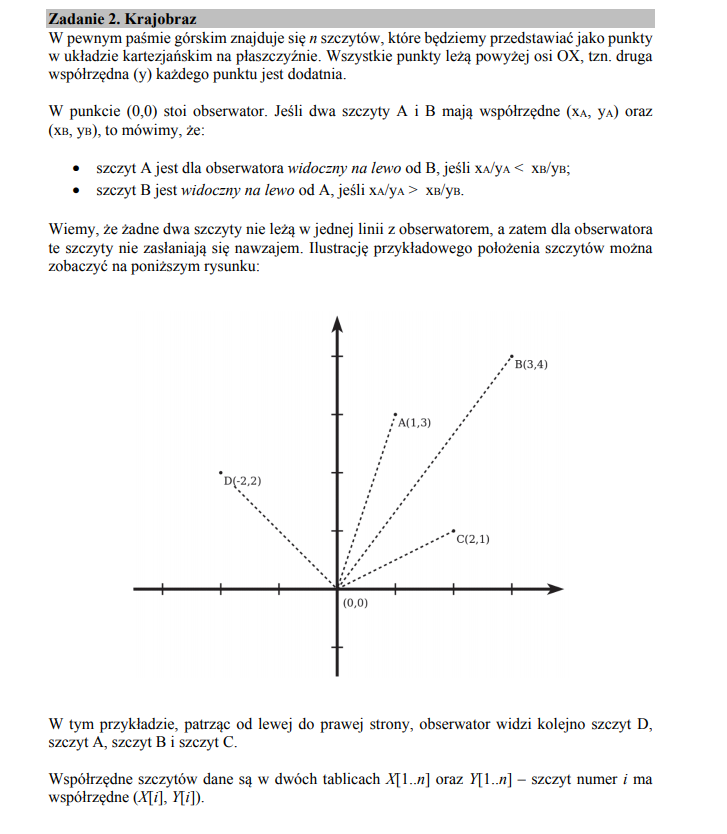
W zadaniu 2 szczególnie ważna jest prawidłowa interpretacja i analiza podanych danych. Istotne będzie również użycie podanych wzorów. W zasadzie to cała matura z informatyki jest oparta na poprawnym zrozumieniu zadań.
Zadanie 2 — podpunkt 1

Do rozwiązania tego zadania możesz użyć dowolnego języka programowania, bądź pseudokodu — dokładnie takiego jaki zawarty był w zadaniu pierwszym. Poniżej znajdziesz kody źródłowe w trzech, dostępnych na maturze językach programowania: Pythonie, Javie i C++:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#include <iostream> using namespace std; int main(){ const int n =4; //zmienna n - ilosc szczytow int X[n] = {1, 3, 2, -2}; //tablica X - wspolrzedne X szczytow int Y[n] = {3, 4, 1, 2}; //tablica Y - wspolrzedne Y szczytow int x = X[0]; // zmienna pomocnicza x - szczyt docelowo najbardziej po lewo, poczatkowo przypisano wspolrzedne x pierwszego szczytu ze zbioru int y = Y[0]; // zmienna pomocnicza y - szczyt docelowo najbardziej po lewo, poczatkowo przypisano wspolrzedne y pierwszego szczytu ze zbioru for (int i = 1; i < n; i++){ //petla for - ilosc iteracji zmniejszona o jeden szczyt( bo przypisalismy go jako pierwszy) if((X[i])/((double)Y[i]) < (x)/((double)y)){ //rzutujemy dzielniki do liczby zmiennoprzecinkowej aby nastapilo dzielenie calkowite;jezeli iterowany szczyt jest bardziej po lewo niz ten zapisany x = X[i]; // przypisz y = Y[i]; // nowe wspolrzedne szczytu } } cout << "Wspolrzedne szczytu najbardziej po lewo: (" << x << ", " << y << ");"; } |
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
public static void main(String[] args) { int n =4; //zmienna n - ilosc szczytow int[] X= {1, 3, 2, -2}; //tablica X - wspolrzedne X szczytow int[] Y = {3, 4, 1, 2}; //tablica Y - wspolrzedne Y szczytow int x = X[0]; // zmienna pomocnicza x - szczyt docelowo najbardziej po lewo, poczatkowo przypisano wspolrzedne x pierwszego szczytu ze zbioru int y = Y[0]; // zmienna pomocnicza y - szczyt docelowo najbardziej po lewo, poczatkowo przypisano wspolrzedne y pierwszego szczytu ze zbioru for (int i = 1; i < n; i++){ //petla for - ilosc iteracji zmniejszona o jeden szczyt( bo przypisalismy go jako pierwszy) if((X[i])/((double)Y[i]) < (x)/((double)y)){ //rzutujemy dzielniki do liczby zmiennoprzecinkowej aby nastapilo dzielenie calkowite;jezeli iterowany szczyt jest bardziej po lewo niz ten zapisany x = X[i]; // przypisz y = Y[i]; // nowe wspolrzedne szczytu } } System.out.println("Wspolrzedne szczytu najbardziej po lewo: (" + x + ", " + y+")"); } |
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
n =4 #zmienna n - ilosc szczytow X = [1, 3, 2, -2] #tablica X - wspolrzedne X szczytow Y = [3, 4, 1, 2] #tablica Y - wspolrzedne Y szczytow x = X[0] # zmienna pomocnicza x - szczyt docelowo najbardziej po lewo, poczatkowo przypisano wspolrzedne x pierwszego szczytu ze zbioru y = Y[0] # zmienna pomocnicza y - szczyt docelowo najbardziej po lewo, poczatkowo przypisano wspolrzedne y pierwszego szczytu ze zbioru for i in range(n-1): #petla for - ilosc iteracji zmniejszona o jeden szczyt( bo przypisalismy go jako pierwszy) for j in range(n-1): if (X[i])/(float(Y[i])) < (x)/(float(y)): #ponownie wykorzystujemy rzutowanie;jezeli iterowany szczyt jest bardziej po prawo, niz szczyt nastepny x1 = X[j+1] # Nastepuje tutaj y1 = Y[j + 1] # zamiana miejsca szczytow w tabelach X[j + 1] = X[j] # te najbardziej po prawo zostana Y[j + 1] = Y[j] # wyrzucone na sam koniec X[j] = x1 # Jest to tzw. Y[j] = y1 # sortowanie babelkowe. for i in range(n): print("(" + str(X[i]) + "), (" + str(Y[i]) + ")") |
Zadanie 2 — podpunkt 2

Do rozwiązania tego podpunktu potrzebne będzie użycie sortowania. Posłużymy się sortowaniem bąbelkowym, aczkolwiek użycie innego sposobu też byłoby poprawne. Poniżej kody źródłowe w trzech możliwych do wyboru językach programowania:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
#include <iostream> using namespace std; int main(){ const int n =4; //zmienna n - ilosc szczytow int X[n] = {1, 3, 2, -2}; //tablica X - wspolrzedne X szczytow int Y[n] = {3, 4, 1, 2}; //tablica Y - wspolrzedne Y szczytow for (int i = 0; i < n; i++){ //petla for - ilosc iteracji zmniejszona o jeden szczyt( bo przypisalismy go jako pierwszy) for(int j=0; j<n-1;j++ ){ if((X[j])/(double)(Y[j]) > (X[j+1])/((double)Y[j+1])){ //ponownie wykorzystujemy rzutowanie;jezeli iterowany szczyt jest bardziej po prawo, niz szczyt nastepny int x1 = X[j+1]; // Nastepuje tutaj int y1 = Y[j+1]; // zamiana miejsca szczytow w tabelach X[j+1] = X[j]; // te najbardziej po prawo zostana Y[j+1] = Y[j]; // wyrzucone na sam koniec X[j] = x1; // Jest to tzw. Y[j] = y1; // sortowanie babelkowe. } } } for(int i = 0; i < n; i++){ // wyrzucenie zawartosci tabeli cout << "(" << X[i] << ", " << Y[i] << ") "; } return 0; } |
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
public static void main(String[] args) { int n = 4; //zmienna n - ilosc szczytow int[] X = { 1, 3, 2, -2 }; //tablica X - wspolrzedne X szczytow int[] Y = { 3, 4, 1, 2 }; //tablica Y - wspolrzedne Y szczytow for (int i = 0; i < n; i++) { //petla for - ilosc iteracji zmniejszona o jeden szczyt( bo przypisalismy go jako pierwszy) for (int j = 0; j < n - 1; j++) { if ((X[j + 1]) / ((double) Y[j + 1]) < (X[j]) / (double)(Y[j])) { //ponownie wykorzystujemy rzutowanie;jezeli iterowany szczyt jest bardziej po prawo, niz szczyt nastepny int x1 = X[j + 1]; // Nastepuje tutaj int y1 = Y[j + 1]; // zamiana miejsca szczytow w tabelach X[j + 1] = X[j]; // te najbardziej po prawo zostana Y[j + 1] = Y[j]; // wyrzucone na sam koniec X[j] = x1; // Jest to tzw. Y[j] = y1; // sortowanie babelkowe. } } } for (int i = 0; i < n; i++) { // wyrzucenie zawartosci tabeli System.out.println("(" + X[i] + ", " + Y[i] + ") "); } } |
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
n =4 #zmienna n - ilosc szczytow X = [1, 3, 2, -2] #tablica X - wspolrzedne X szczytow Y = [3, 4, 1, 2] #tablica Y - wspolrzedne Y szczytow for i in range(n-1): #petla for - ilosc iteracji zmniejszona o jeden szczyt( bo przypisalismy go jako pierwszy) for j in range(n-1): if (X[i])/(float(Y[i])) < (X[i+1])/(float(Y[i+1])): #ponownie wykorzystujemy rzutowanie;jezeli iterowany szczyt jest bardziej po prawo, niz szczyt nastepny x1 = X[j+1] # Nastepuje tutaj y1 = Y[j + 1] # zamiana miejsca szczytow w tabelach X[j + 1] = X[j] # te najbardziej po prawo zostana Y[j + 1] = Y[j] # wyrzucone na sam koniec X[j] = x1 # Jest to tzw. Y[j] = y1 # sortowanie babelkowe. for i in range(n): print("(" + str(X[i]) + "), (" + str(Y[i]) + ")") |
Matura z informatyki 2018 odpowiedzi: Zadanie 3 — prawda/fałsz
Cóż tu więcej tłumaczyć — do wykonania tego zadania wymagana była podstawowa wiedza o językach PHP, SQL, JavaScript i o kolorach w standardzie CMYK. Warto pamiętać, że aby zdobyć punkty za jeden podpunkt, należy go bezbłędnie wykonać — jedna skucha = 0 punktów. Odpowiedzi zostały zaznaczone na zdjęciu:


Matura z informatyki 2018 rozwiązania — część druga (praktyka)
Składająca się z 3 zadań część 2 egzaminu maturalnego z informatyki, według danych podanych przez CKE, sprawiła większy problem, niż teoretyczna część. Poniżej jednak podamy poprawne odpowiedzi wraz z rozwiazaniami.
Matura z informatyki 2018 odpowiedzi: Zadanie 4 — WEGA

W tym zadaniu bez wątpienia potrzebny będzie program odczytujący dane z pliku — w końcu komu by się chciało szukać pojedynczych liter w 1000 wierszach? Podamy więc prosty program w językach C++, Java i Python, który otworzy plik i wydrukuje w konsoli jego zawartość — modyfikując go wykonamy kolejne polecenia. Plik sygnaly.txt znajdziecie pod tym linkiem.
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#include <iostream> #include <fstream> using namespace std; int main(){ string line; ifstream file("sygnaly.txt"); // otwieranie - nalezy podac lokalizacje pliku if(file.is_open()){ while (getline (file,line)){ // iteracja linii cout << line << endl; //drukowanie linii } file.close(); // zamkniecie pliku } return 0; } |
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
package matura; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; public class Main { public static void main(String[] args) throws IOException { String line; File f = new File("sygnaly.txt"); // otwieranie - nalezy podac lokalizacje pliku if (!f.exists()) { //sprawdzamy najpierw, czy aby napewno plik istnieje System.out.println("Nie znalezniono pliku"); // jezeli nie, zwracamy komunikat return; } BufferedReader br = new BufferedReader(new FileReader(f)); // w przeciwnmym wypadku tworzymy instancje BufferedReader - czytnika umozliwajacego sprawdzenie zawartosci pliku if (br.ready()) { // jezeli jest on gotowy while ((line = br.readLine()) != null) { // iteracja linii System.out.println(line); } br.close(); // zamkniecie pliku } } } |
Python
|
1 2 3 4 5 6 7 |
file = open("sygnaly.txt", "r") #otwieranie - nalezy podac lokalizacje pliku i parametr "r" - read if file.closed: #jeżeli plik został zamknięty print("Nie można odnaleźć pliku") #zakończ działanie programu exit(0); for line in file: #wczytuj każdy wiersz z pliku print(line) #i drukuj file.close() #zamknij plik |
Zadanie 4 — podpunkt 1

Modyfikujemy więc powyższy kod tak, aby spełniał warunki zadania:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#include <iostream> #include <fstream> using namespace std; int main(){ string line; string final = ""; // inicjalizacja zmiennej przechowujacej finalny tekst ifstream file("sygnaly.txt"); int n = 1; // uzywamy zmiennej pomocniczej, aby przechowac aktualny numer wiersza if(file.is_open()){ while (getline (file,line)){ if(n % 40 == 0) // jezeli wiersz jest wielokrotnoscia liczby 40 final = final + line[9]; // dodaje do finalnego slowa 10 litere wiersza n++; // zwiekszenie liczby wierszy o 1 } file.close(); cout << final; } return 0; } |
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
package matura; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; public class Main { public static void main(String[] args) throws IOException { String line; File f = new File("sygnaly.txt"); // otwieranie - nalezy podac lokalizacje pliku if (!f.exists()) { //sprawdzamy najpierw, czy aby napewno plik istnieje System.out.println("Nie znalezniono pliku"); // jezeli nie, zwracamy komunikat return; } BufferedReader br = new BufferedReader(new FileReader(f)); // w przeciwnmym wypadku tworzymy instancje BufferedReader - czytnika umozliwajacego sprawdzenie zawartosci pliku if (br.ready()) { // jezeli jest on gotowy String Final = ""; // inicjalizacja zmiennej przechowujacej finalny tekst int n = 1; // uzywamy zmiennej pomocniczej, aby przechowac aktualny numer wiersza while ((line = br.readLine()) != null) { // iteracja linii if (n % 40 == 0) // jezeli wiersz jest wielokrotnoscia liczby 40 { Final = Final + line.charAt(9); // dodaje do finalnego slowa 10 litere wiersza } n++; // zwiekszenie liczby wierszy o 1 } br.close(); // zamkniecie pliku System.out.println(Final); //wypisujemy wynik } } } |
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 |
file = open("sygnaly.txt", "r") #otwieranie - nalezy podac lokalizacje pliku i parametr "r" - read if file.closed: #jeżeli plik został zamknięty print("Nie można odnaleźć pliku") #zakończ działanie programu exit(0); final = "" #zmienna kontener, ktora przechowa slowo n = 1; #zmienna pomocnicza do iteracji for line in file: #wczytuj każdy wiersz z pliku if n % 40 == 0: #co cztedziesta linjke final = final + line[9] #dodaj do wyrazu dziesiata litere z wiersza n += 1 #zwiekszamy zmienna pomocnicza file.close() #zamknij plik print(final) #drukuj wynik |
Wynikiem powyższego programu jest: ZAPISZODPOWIEDZIWPLIKUTXT.
Zadanie 4 — podpunkt 2

W tym zadaniu musimy dla każdego wyrazu stworzyć zbiór unikalnych liter, następnie sprawdzić ich ilość, a następnie porównać z dotychczas znalezionym wynikiem. Zwracamy uwagę, że należy dodać odpowiednią dyrektywę #include <set> w języku C++ oraz zaimportować java.util.ArrayList w Javie. W języku Python musimy wziąć pod uwagę, że przy wczytywaniu znaków z wiersza ostatnim będzie zawsze „\n” oznaczający jego koniec i początek kolejnej linijki.
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
#include <iostream> #include <fstream> #include <set> // NALEZY DODAC TA DYREKTYWE! using namespace std; int main(){ string line; string word; // zmienna przechowujaca najdluzsze slowo ifstream file("sygnaly.txt"); int max = 0; // zmienna przechowujaca dlugosc najdluzsego slowa if(file.is_open()){ while (getline (file,line)){ set<char> chars; // zbior przechowujacy niepowtarzalne literki int f = 0; //ilosc znalezionych niepowatrzalnych literek for(int i = 0; i < line.length(); i++){ //iteracja przez wiersz if(chars.find(line[i]) != chars.end()) //jezeli zbior zawiera juz ta literke continue; //przejdz do nastepnego iterowanego wyrazu chars.insert(line[i]); //dodaj do zbioru nowa literke f++; //zwieksz ilosc znalezionych liter } if(f > max){ //jezeli ilosc znalezionych liter jest wieksza niz dotychczas max = f; // podmien ja word = line; // i wyraz } } file.close(); cout << word << endl << max << " liter"; } return 0; } |
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
package matura; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; import java.util.ArrayList; // należy dodać ten import! public class Main { public static void main(String[] args) throws IOException { String line; String word = ""; // zmienna przechowujaca najdluzsze slowo int max = 0; // zmienna przechowujaca dlugosc najdluzsego slowa File f = new File("sygnaly.txt"); // otwieranie - nalezy podac lokalizacje pliku if (!f.exists()) { //sprawdzamy najpierw, czy aby napewno plik istnieje System.out.println("Nie znalezniono pliku"); // jezeli nie, zwracamy komunikat return; } BufferedReader br = new BufferedReader(new FileReader(f)); // w przeciwnmym wypadku tworzymy instancje BufferedReader - czytnika umozliwajacego sprawdzenie zawartosci pliku if (br.ready()) { // jezeli jest on gotowy while ((line = br.readLine()) != null) { // iteracja linii int k = 0; //ilosc znalezionych niepowatrzalnych litere ArrayList < Character > chars = new ArrayList < Character > (); // zbior przechowujacy niepowtarzalne literki for (int i = 0; i < line.length(); i++) { //iteracja przez wiersz if (chars.contains(line.charAt(i))) //jezeli zbior zawiera juz ta literke continue; //przejdz do nastepnego iterowanego wyrazu chars.add(line.charAt(i)); //w przeciwnym wypadku dodaj do zbioru nowa literke k++; //zwieksz ilosc znalezionych liter } if (k > max) { //jezeli ilosc znalezionych liter jest wieksza niz dotychczas max = k; // podmien ja word = line; // i wyraz } } br.close(); // zamkniecie pliku } System.out.println(word); System.out.println(max + " liter"); // wypisujemy słowo i jego długość } } |
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
file = open("sygnaly.txt", "r") #otwieranie - nalezy podac lokalizacje pliku i parametr "r" - read if file.closed: #jeżeli plik został zamknięty print("Nie można odnaleźć pliku") #zakończ działanie programu exit(0); word = ""# zmienna przechowujaca najdluzsze slowo max = 0 # zmienna przechowujaca dlugosc najdluzsego slowa for line in file: #wczytuj każdy wiersz z pliku k = 0 #ilosc znalezionych niepowatrzalnych literek chars = [] #zbior przechowujacy niepowtarzalne literki for char in line: #iterujemy poprzez znaki wyrazu if chars.__contains__(char) or char == "\n": ## jezeli juz wczesniej znalezlismy ta litere LUB jest to znak nowej linijki continue; #to ja pomijamy chars.append(char); # w przeciwnym razie dodajemy do zbioru k += 1 #i zwiekszamy ilosc znalezionych literek if(k > max): #jezeli ilosc ta bedzie wieksza niz dotychczasowa max = k #to podmieniamy ja word = line #oraz slowo file.close() #zamknij plik print(word) #i drukuj print(str(max) + " liter") #wynik |
Wynikiem programu będzie słowo składające się z 26 liter.
Zadanie 4 — podpunkt 3

W tym podpunkcie posłużymy się faktem, że w języku C++ możliwe jest obliczenie różnicy pomiędzy literkami — da nam ona ich odległość w alfabecie. Tym razem potrzebna będzie potrzebny import biblioteki
<math.h> w języku C++. W Javie korzystamy ze statycznej metody z klasy Math, zaś w Pythonie musimy znowu, tak jak w poprzednim podpunkcie, pominąć znak „\n” przy odczycie:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
#include <iostream> #include <fstream> #include <math.h> // NALEZY DODAC TA DYREKTYWE! using namespace std; int main(){ string line; string words; // zmienna przechowujaca wyrazy ifstream file("sygnaly.txt"); if(file.is_open()){ while (getline (file,line)){ bool b = true; // zmienna pomocnicza, wskazujaca czy dany wyraz spelnia wymagania for(int i = 0; i<line.length(); i++){ //petla iterujaca poprzez kazda litere if(b){ for (int j = i+1; j < line.length(); j++){ //petla iterujaca przez kazda inna litere, w celu sprawdzenia roznicy int difference = abs(line[i] - line[j]); //obliczenie roznicy if(difference > 10) b=false; } } else break; } if(b) words = words + "\n" + line; //dodanie slowa } file.close(); cout << words; } return 0; } |
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
package matura; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; public class Main { public static void main(String[] args) throws IOException { String line; String words = ""; // zmienna przechowujaca wyrazy File f = new File("sygnaly.txt"); // otwieranie - nalezy podac lokalizacje pliku if (!f.exists()) { //sprawdzamy najpierw, czy aby napewno plik istnieje System.out.println("Nie znalezniono pliku"); // jezeli nie, zwracamy komunikat return; } BufferedReader br = new BufferedReader(new FileReader(f)); // w przeciwnmym wypadku tworzymy instancje BufferedReader - czytnika umozliwajacego sprawdzenie zawartosci pliku if (br.ready()) { // jezeli jest on gotowy while ((line = br.readLine()) != null) { // iteracja linii boolean b = true; // zmienna pomocnicza, wskazujaca czy dany wyraz spelnia wymagania for (int i = 0; i < line.length(); i++) { //petla iterujaca poprzez kazda litere if (b) { for (int j = i + 1; j < line.length(); j++) { //petla iterujaca przez kazda inna litere, w celu sprawdzenia roznicy int diff = Math.abs(line.charAt(i) - line.charAt(j)); //obliczenie roznicy if (diff > 10) b = false; } } else break; } if (b) { words = words + "\n" + line; //dodanie slowa } } br.close(); // zamkniecie pliku } System.out.println(words); // wypisanie wyniku } } |
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
file = open("sygnaly.txt", "r") #otwieranie - nalezy podac lokalizacje pliku i parametr "r" - read if file.closed: #jeżeli plik został zamknięty print("Nie można odnaleźć pliku") #zakończ działanie programu exit(0) words = "" for line in file: #wczytuj każdy wiersz z pliku b = True #zmienna pomocnicza, wskazujaca czy dany wyraz spelnia wymagania for char in line: #petla iterujaca poprzez kazda litere if char == "\n": # musimy znowu sprawdzic, czy nie natrafilismy na znak rozpoczynajacy nastepny wiersz continue if b: for char2 in line[1:]: #petla iterujaca przez kazda inna litere, w celu sprawdzenia roznicy if char2 == "\n": # musimy znowu sprawdzic, czy nie natrafilismy na znak rozpoczynajacy nastepny wiersz continue diff = abs(ord(char) - ord(char2)) #obliczenie roznicy if diff > 10: #jezeli roznica jest wieksza niz 10 b = False #nie dodawaja tego wyrazu do listy else: break if b: words = words + "\n" + line #jezeli jednak wyraz spelnial wymogi, dodaj go do listy file.close() #zamknij plik print(words) #i drukuj wynik |
Matura z informatyki 2018: zadanie 5 — wylewy Wirki

W tym zadaniu dostajemy nieco większe pole do popisu — do dyspozycji mamy wszelkie narzędzia informatyczne dostępne pod ręką. Możliwe jest więc napisanie specjalnego programu do odczytu danych, jednakże znacznie lepszym rozwiązaniem będzie tutaj wykorzystanie importu danych w programie Microsoft Excel. Przedstawiamy krok po kroku jak to zrobić:
- Wybieramy Dane>Z tekstu
- Wybieramy plik z danymi
- Bez zmian.
- Również bez zmian.
- Należy zmienić format daty, tak jak na zdjęciu:
- Tutaj bez zmian.
- Warto również „obniżyć” dane (ctrl+a, a następnie przesunąć myszką o jeden wiersz w dół), aby dodać tytuły kolumn:
Zadanie 5 — podpunkt 1

Gdy już zaimportowaliśmy dane i podzieliliśmy je na kolumny, należy stworzyć kolejną kolumnę, w której będą wyciągnięte jedynie lata z podanej daty. Do tego przyda nam się formułą ROK — w komórce C1 wpisujemy tytuł kolumny „Rok”, a w komórce C2 wpisujemy formułe =ROK(A2). Następnie łapiemy myszką za mały kwadracik i przeciągamy aż do ostatniego wiersza.
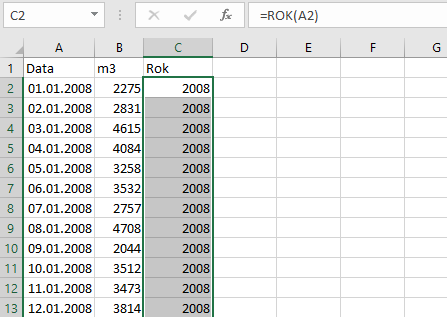
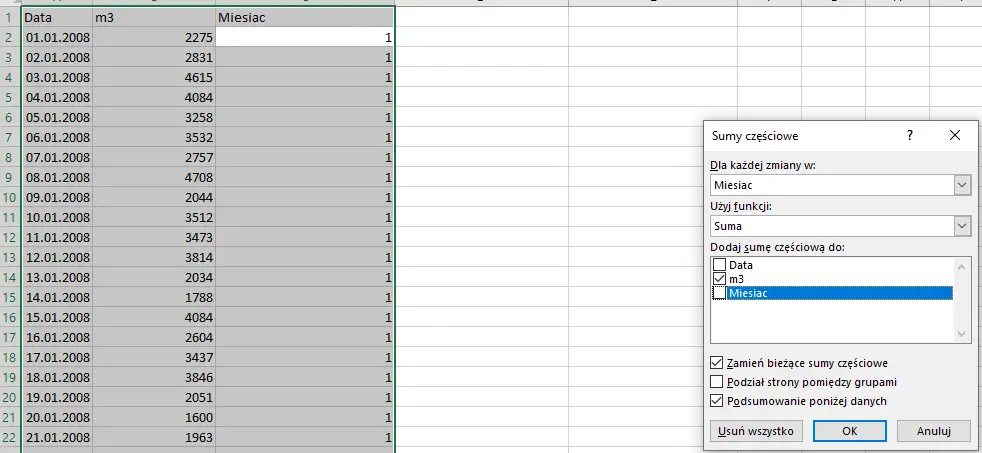
Następnym krokiem jest wykorzystanie Sumy częściowej z zakładki dane:
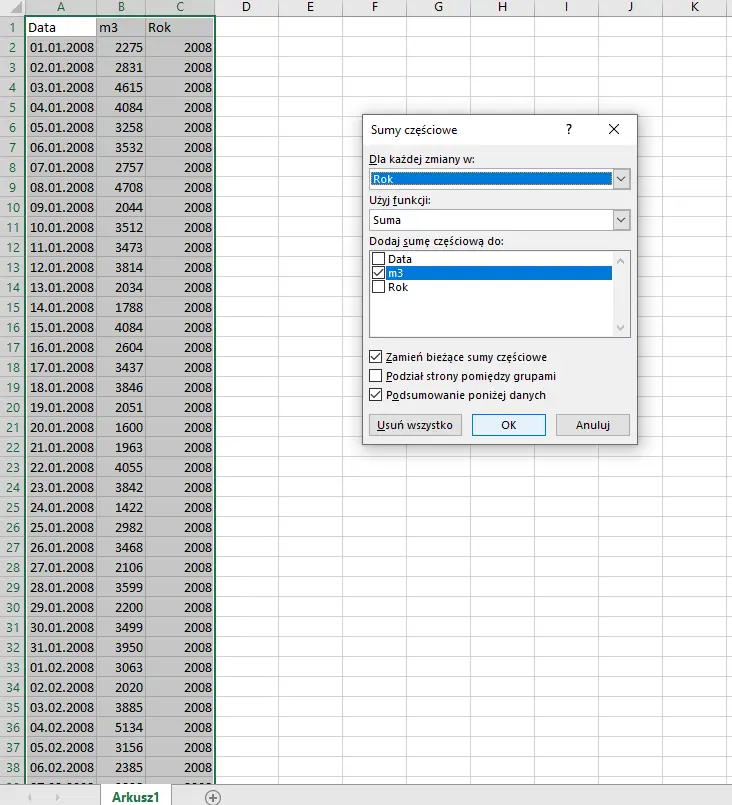
Okienko wypełniamy tak jak na powyższym obrazku. Zwracamy uwagę, że aby uruchomić sumę częściową należy najpierw zaznaczyć obszar, w którym są dane (można użyć ctrl+a). Następnie, po kliknięciu OK, z boku pojawią się 3 zakładki. Wchodzimy w zakładkę numer 2, a następnie rozszerzamy kolumnę m3.
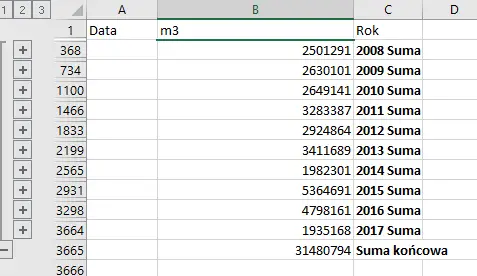
Następnie zaznaczamy wartości w kolumnie m3, klikamy prawym przyciskiem myszy i należy wybrać Sortuj>Sortuj od największej do najmniejszej. Po tej operacji na samej górze ujrzymy rok, w którym zbiornik został zasilony największą ilością wody.
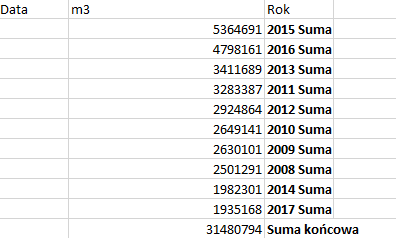
Odpowiedzią jest rok 2015.
Zadanie 5 — podpunkt 2

W tym zadaniu musimy po 1. znaleźć dni, w których ilość wody przekracza 10000 m3, a następnie należy odnaleźć najdłuższy okres, w którym te wartości się utrzymywały. W tym celu utworzymy kolejne kolumny z nowymi formułami, jednakże zanim do tego przejdziemy należy posortować całą kolumnę Data — od najstarszej do najnowszej:
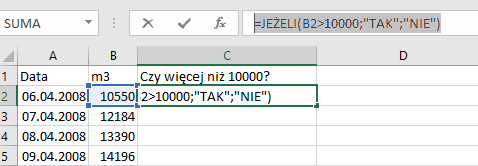
Następnie tworzymy kolumnę Czy więcej niż 10000? — w pierwszej komórce pod tytułem zamieszczamy zaś formułę =JEŻELI(B2>10000;”TAK”;”NIE”), a następnie „przeciągamy” ją na całą kolumnę. Teraz gdy w danym dniu było więcej niż 10000 m3 wody, to komórka przyjmie wartość TAK, a w przeciwnym wypadku NIE.
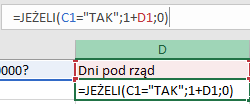
Następnie tworzymy kolumnę Ilość dni pod rząd, a w pierwszej komórce formuła =JEŻELI(C1=”TAK”;1+D1;0). Komórki będą przyjmować wartość o 1 większą od poprzedniej, jeżeli nadal ilość wody będzie przekraczać 10000 m3.
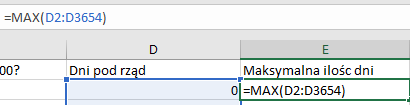
Teraz, dla ułatwienia, można stworzyć kolumnę Maksymalna ilość dni, w której wybierzemy z całego okresu największą ilość dni pod rząd, aby potem było łatwiej ją odszukać.
Gdy już mamy maksymalną ilość dni odszukujemy ją, a następnie odczytujemy zakres dat.
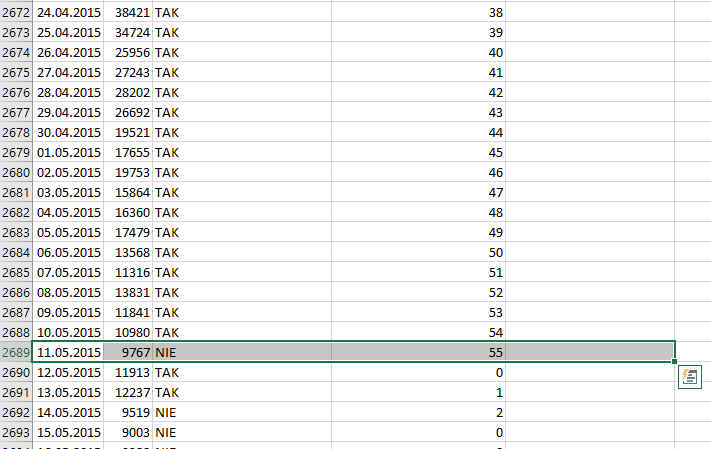
Odpowiedzią jest więc 55 dni, w okresie od 2015—03—17, do 2015—05—10.
Zadanie 5 — podpunkt 3

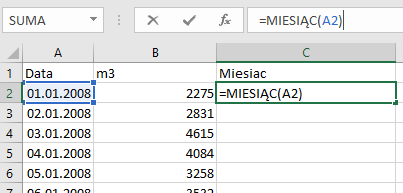
W tym zadaniu wykorzystamy ponownie sumę częściową. Utworzymy w tym celu nową kolumnę Miesiąc z komórkami używającymi formuły =MIESIĄC.
Tutaj znów pomocne będzie posortowanie danych według daty — łatwiej będzie zaznaczyć dane z kolumny m3.
Tworzymy kolejną kolumnę, a następnie wpisujemy formułę tak jak na obrazku. Następnie „przeciągamy” daną formułę na całą kolumnę.
Następnym krokiem jest wygenerowanie sumy częściowej. W tym celu zaznaczamy wszystkie komórki (ctrl+a), a potem wybieramy Suma częściowa, z zakładki Dane. Okienko uzupełniamy tak jak pokazano na obrazku powyżej.
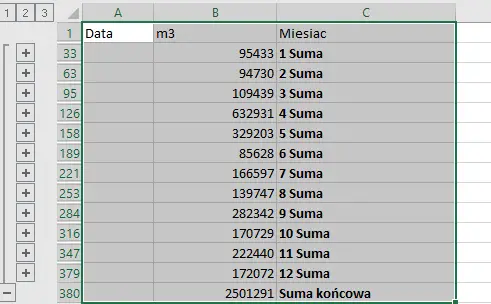
Teraz zaznaczamy dane z interesującego nas okresu (jeżeli posortowałeś daty, to będą to pierwsze 13 wierszy). Dobrym pomysłem jest ich przeniesienie do nowego arkusza, aby ułatwić tworzenie wykresu. W tym celu należy wcisnąć klawisz F5, wybrać Specjalnie…>Tylko widoczne komórki, a potem skopiować i wkleić w nowym arkuszu.
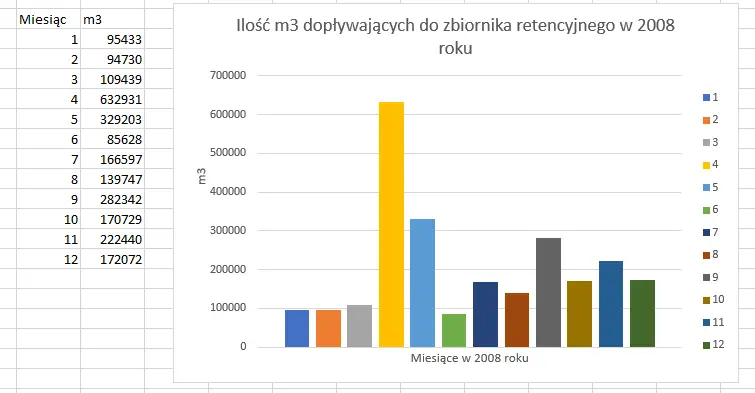
Po odpowiednim ułożeniu danych można przystąpić do tworzenia wykresu kolumnowego z zakładki Wstawianie. Ważne jest, aby odpowiednio podpisać wykres.
Zadanie 5 — podpunkt 4

- W tym celu należy utworzyć dodatkowe kolumny z formułami takimi, jak na zdjęciach: Formuła =JEZELI jest tu wymagana ze względu na fakt, że objętość wody była obniżana równo do 1 miliona m3 w sytuacji, gdy go przekroczyła. Trzecia kolumna jest kolumną pomocniczą ułatwiającą znalezienie pierwszego dnia, w którym woda była upuszczana. Zwracam uwagę, że sprawdza ona, czy objętość jest większa lub równa 1000001 metrów sześciennych — pozwoli to uniknąć sytuacji, gdzie poziom wody po zasileniu byłby dokładnie równy 1000000 m3. Następnym krokiem jest złapanie za trzy komórki z nowo utworzonych kolumn i przeciągnięcie ich na wszystkie dane. Z arkusza jasno wynika, że pierwszym takim dniem był 19.04.2015.
- W tym podpunkcie wystarczy utworzyć dodatkową kolumnę Czy więcej niż 800000m3?, a w pierwszej komórce umieścić odpowiednią formułę, a następnie rozszerzyć ją na całą kolumnę: Następnie wystarczy utworzyć kolumnę zliczającą wszystkie komórki z utworzonego przedziału: Odpowiedź to 188 dni.
- W tym celu wystarczy po prostu zmodyfikować poprzednio wykorzystywaną formułę w komórce C2, a następnie należy ją rozszerzyć na całą kolumnę: Potem już tylko trzeba znaleźć maksymalną zawartość z kolumny C: Odpowiedź to 1 399 242 m3.

Matura z informatyki 2018 arkusz — zadanie 6


Po przejrzeniu i analizie danych z plików komputery.txt, awarie.txt oraz naprawy.txt od razu widać, że są to powiązane ze sobą tabele bazy danych. Można by tutaj użyć phpMyAdmin, jednakże ze względu na przyjaźniejszy interfejs i wygodę importu najlepiej skorzystać z programu Microsoft Access. Rozpoczniemy więc od zaimportowania tabel. Ze względu na relacje należy wgrać je w kolejności komputery > awarie > naprawy.
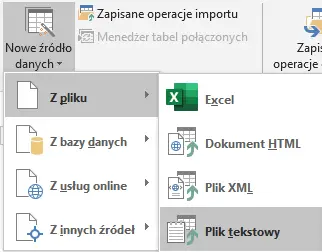
Wybieramy Dane zewnętrzne>Nowe źródło danych > Plik tekstowy, a następnie wybieramy plik komputery.txt. W kolejnych krokach postępuj tak jak pokazano na obrazkach.
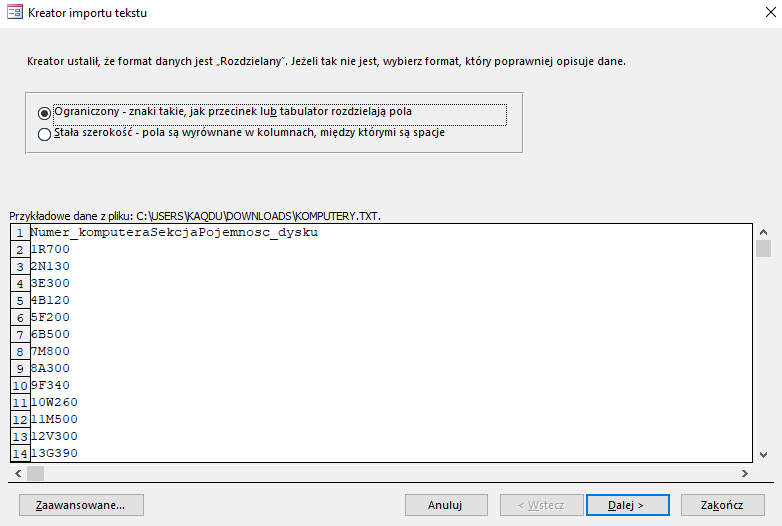
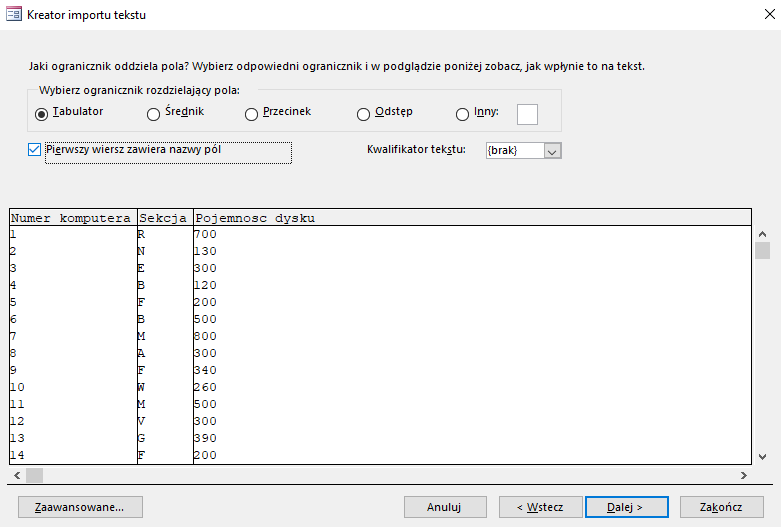
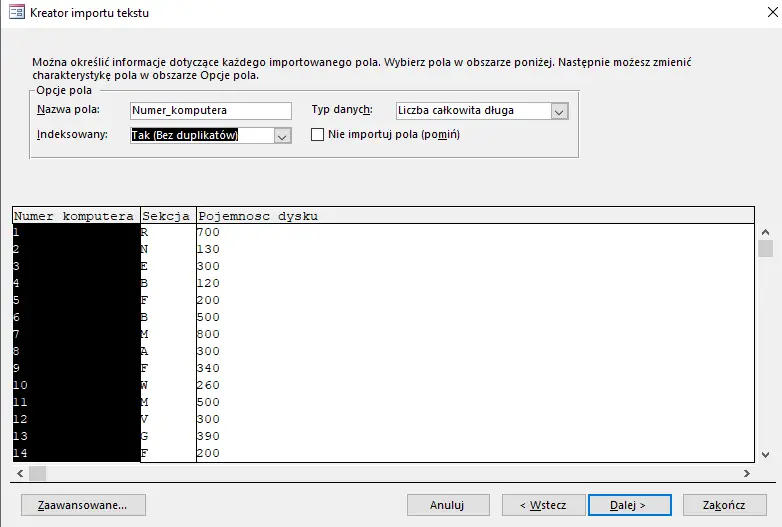
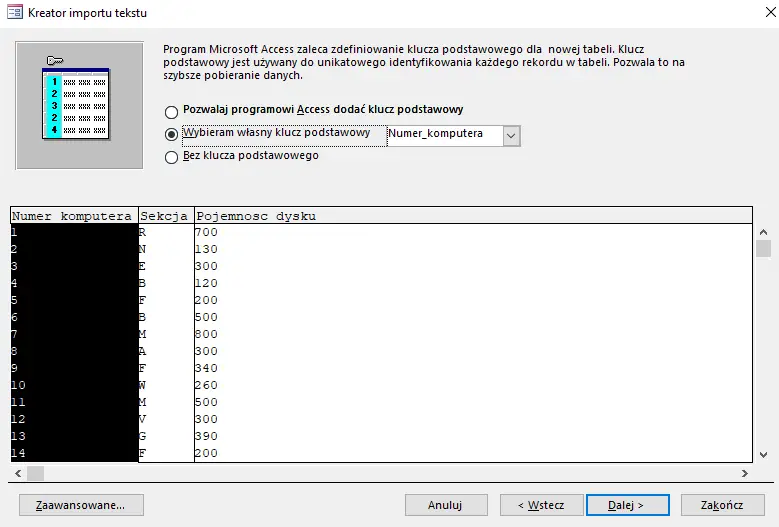
Procedurę importu powtarzamy analogicznie dla plików awarie i naprawy. UWAGA: Przy imporcie pozostałych plików w drugim okienku należy kliknąć Zaawansowane i zmienić format daty na RMD.
Kolejnym krokiem jest utworzenie relacji. Wybieramy Narzędzia bazy danych>Relacje i tworzymy relacje zgodnie z obrazkiem:
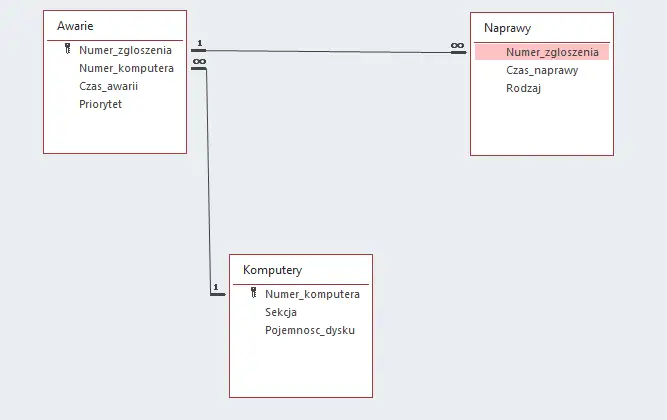
Z tak przygotowaną bazą danych możemy przystąpić do rozwiązywania zadania.
Zadanie 6 — podpunkt 1

Wykorzystamy kwerendę — w tym celu wchodzimy w Tworzenie>Kreator kwerend, a następnie dodajemy tabelę Komputery.
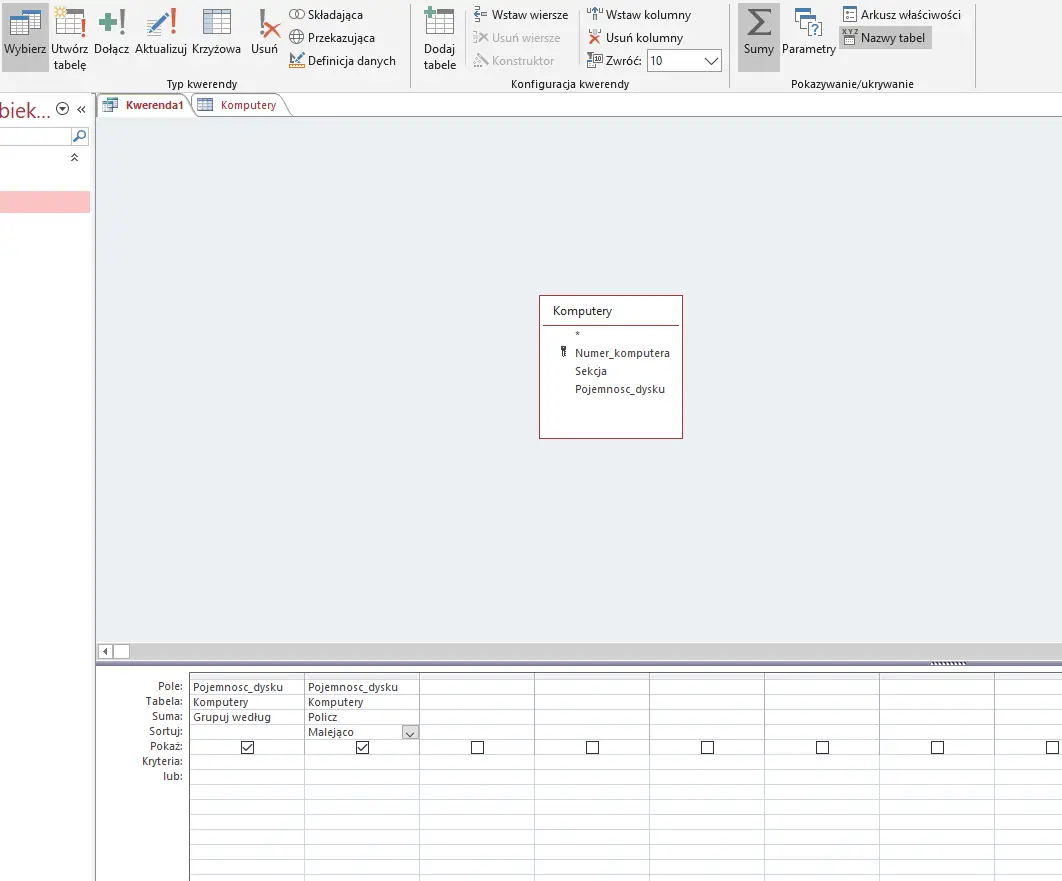
Musimy wybrać kolumnę Pojemnosc_dysku dwukrotnie tak jak na zdjęciu. Następnie klikamy Sumy w prawym górnym rogu, po czym uzupełniamy projekt tak jak na zdjęciu. Na koniec należy ograniczyć ilość wyszukanych wyników do 10 tuż obok przycisku Sumy.
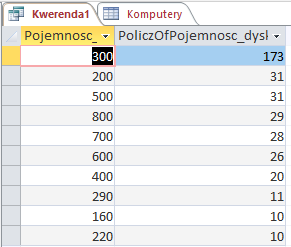
Wynik kwerendy powinien być taki, jak na zdjęciu.
Zadanie 6 — podpunkt 2

Tym razem w kwerendzie potrzebować będziemy wszystkich tabel — niestety w tabeli Naprawy brakuje odwołania do tabeli Komputery, dlatego trzeba posłużyć się tabelą Awarie.
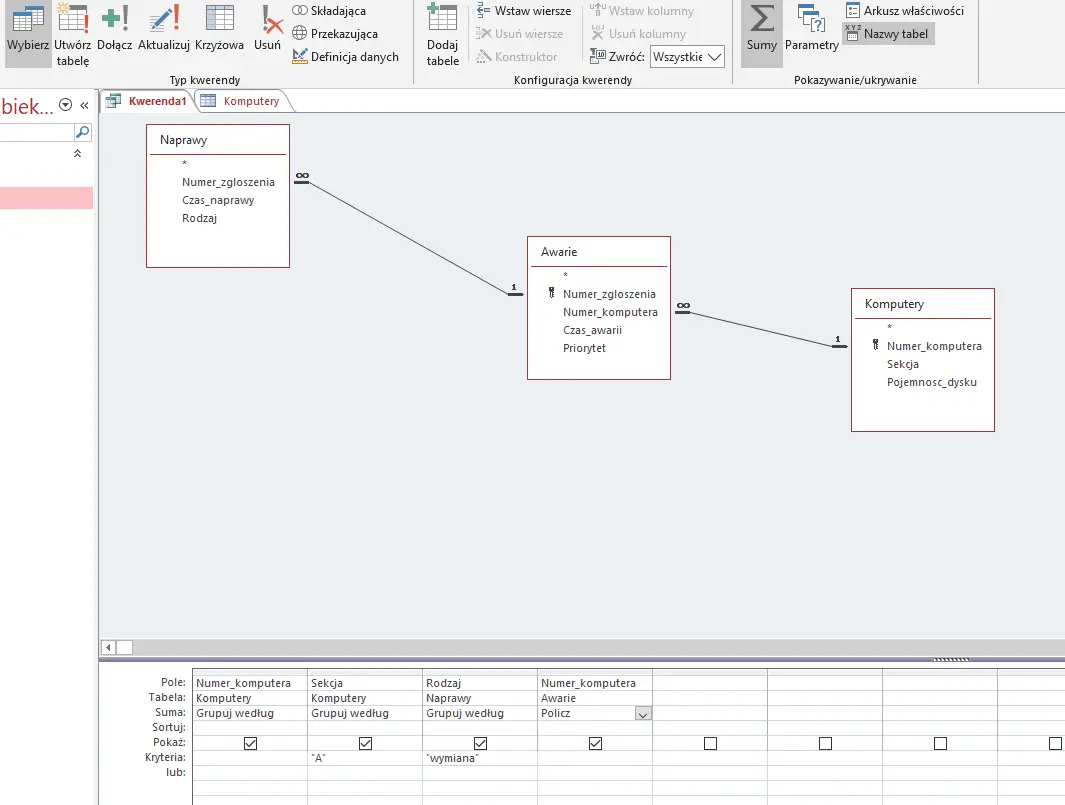
Uzupełniamy projekt o wymogi zadania, pamiętając aby zwracać uwagę na wielkość liter przy kryteriach.

Wynik działania kwerendy widoczny jest na obrazku.
Zadanie 6 — podpunkt 4

W tym celu potrzebne będzie utworzenie trzech kwerend pomocniczych:
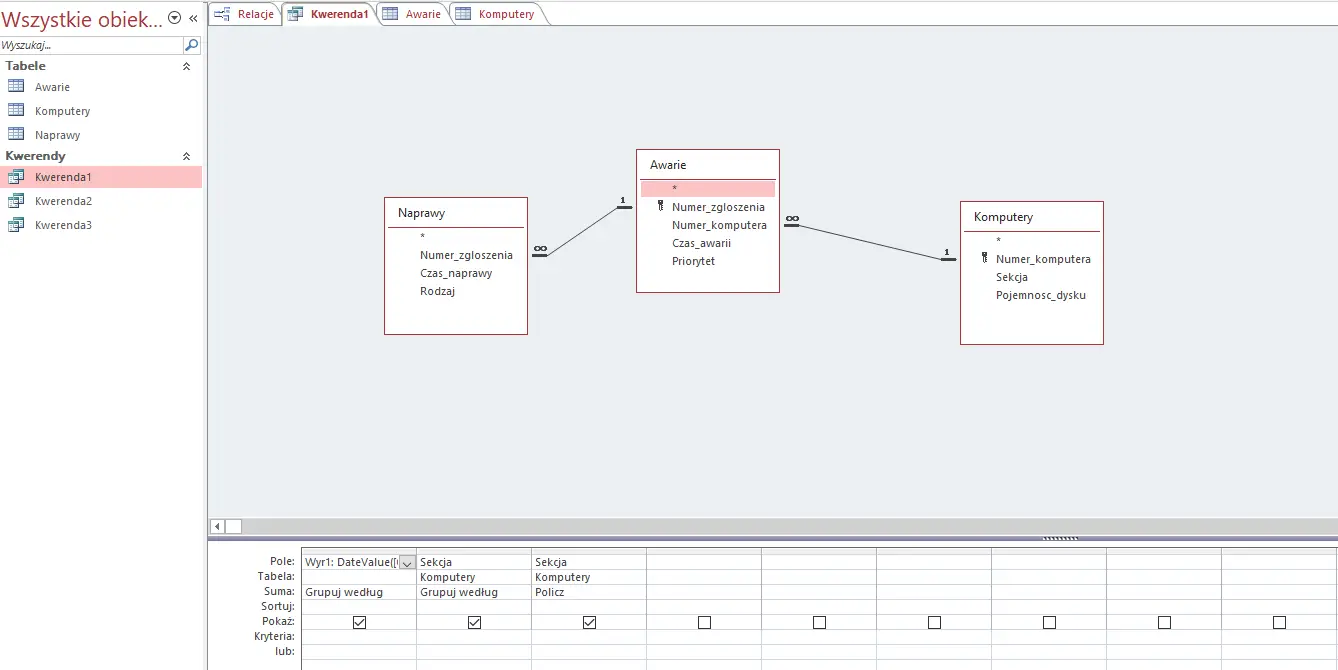
Pierwsza kwerenda zliczająca ilość awarii w danym dni i dla każdej sekcji.
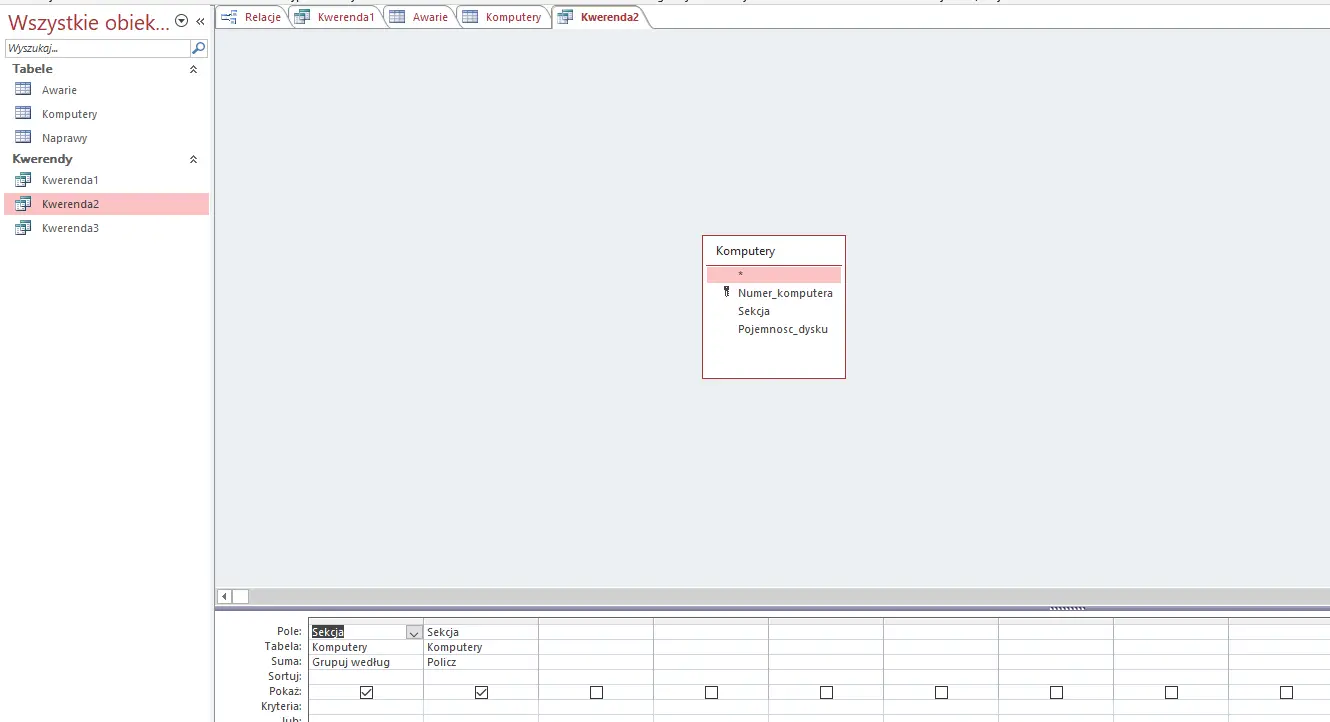
Druga kwerenda zliczająca ilość komputerów w danej sekcji.
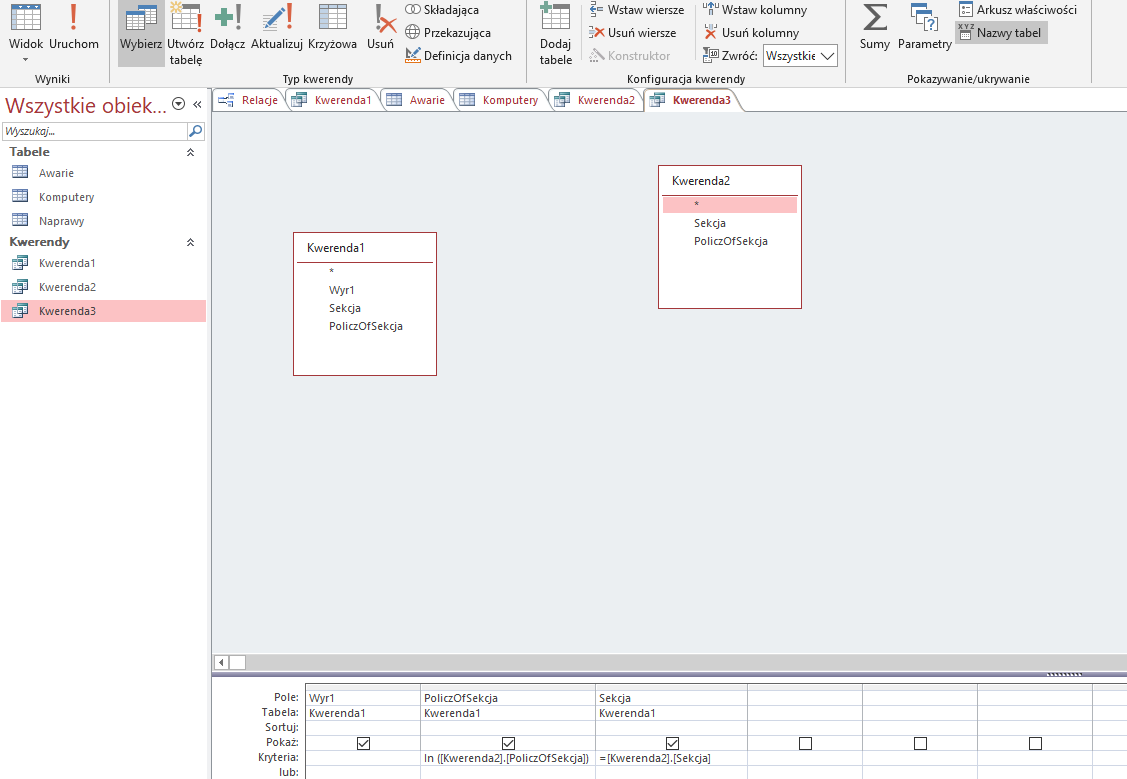
Ostatnia kwerenda, która porównuje dwie poprzednie — da nam ona rozwiązanie zadania:

Zadanie 6 — podpunkt 4

W tym podpunkcie do kwerendy potrzebne będą nam dwie tabele: awarie i naprawy. Obliczymy różnice czasu pomiędzy naprawą, a zgłoszeniem awarii, posortujemy wyniki, ograniczymy je do jednego i wydrukujemy pożądane dane — wszystko widoczne jest na obrazku:
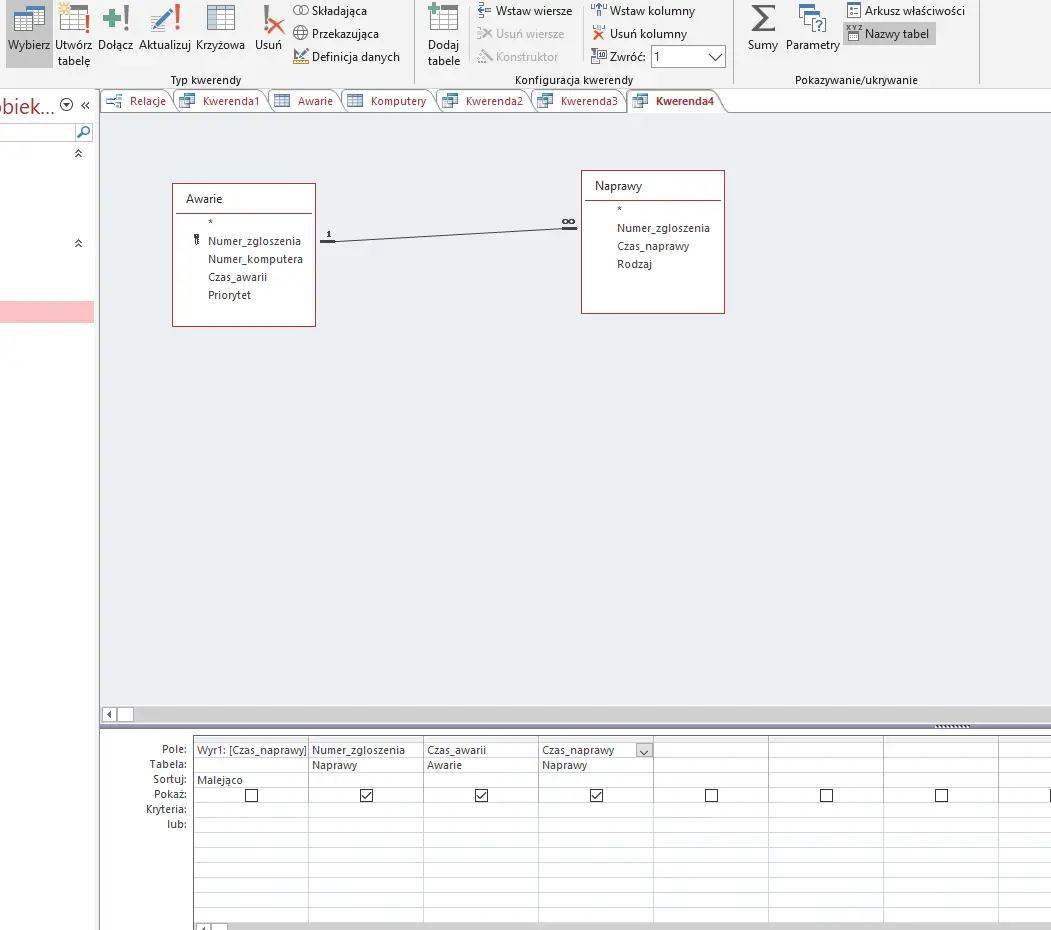
Kwerenda ta daje nam wynik:

Zadanie 6 — podpunkt 5

W tym podpunkcie wymagane będzie stworzenie kilku pomocniczych kwerend:
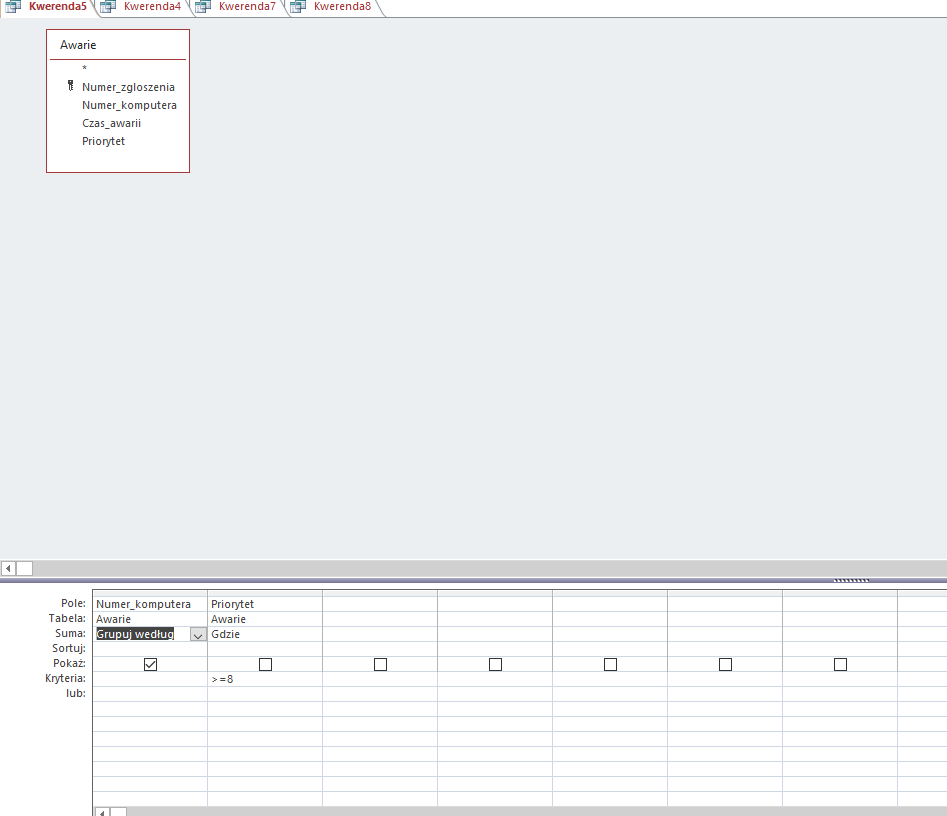
Pierwsza kwerenda wybierająca komputery, które miały awarie o priorytecie większym lub równym 8. Dlaczego tak? Dlatego, że odejmując ilość takich awarii od ilości wszystkich komputerów uzyskamy liczbę komputerów, które nie miały takich awarii.
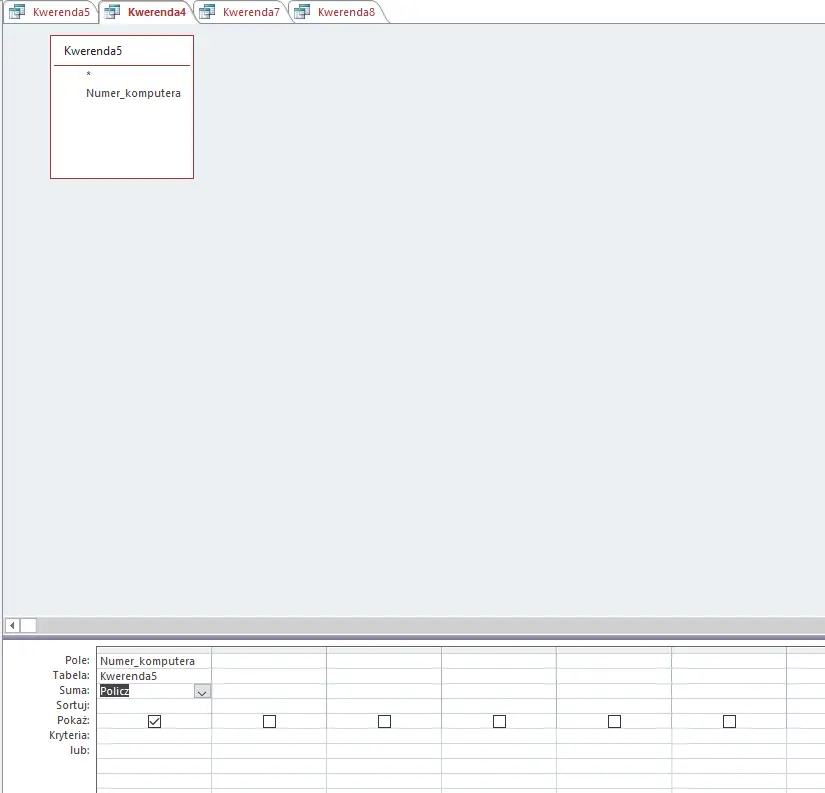
Następna kwerenda będzie miała za zadanie zliczenie komputerów z poprzedniej kwerendy.
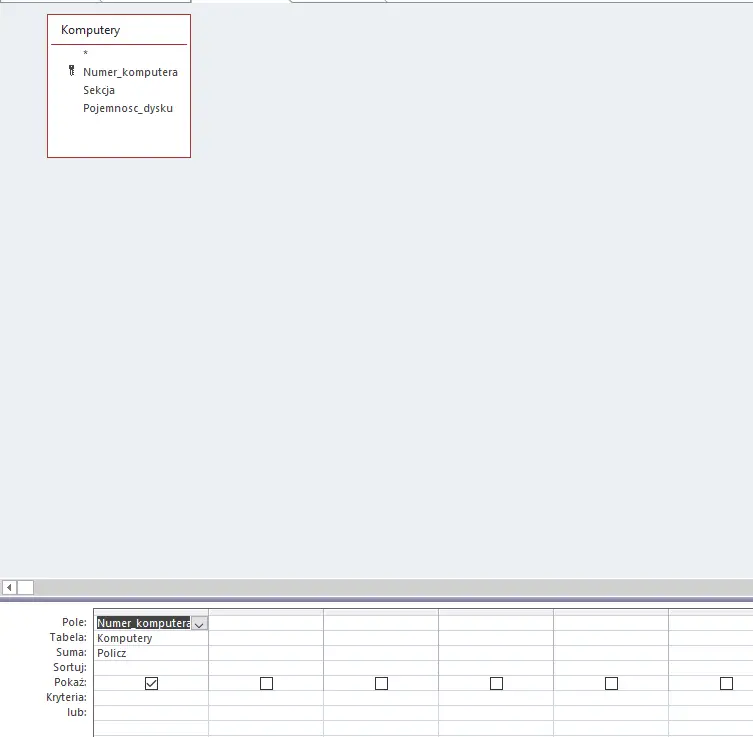
Kolejna kwerenda zliczy ilość wszystkich komputerów.
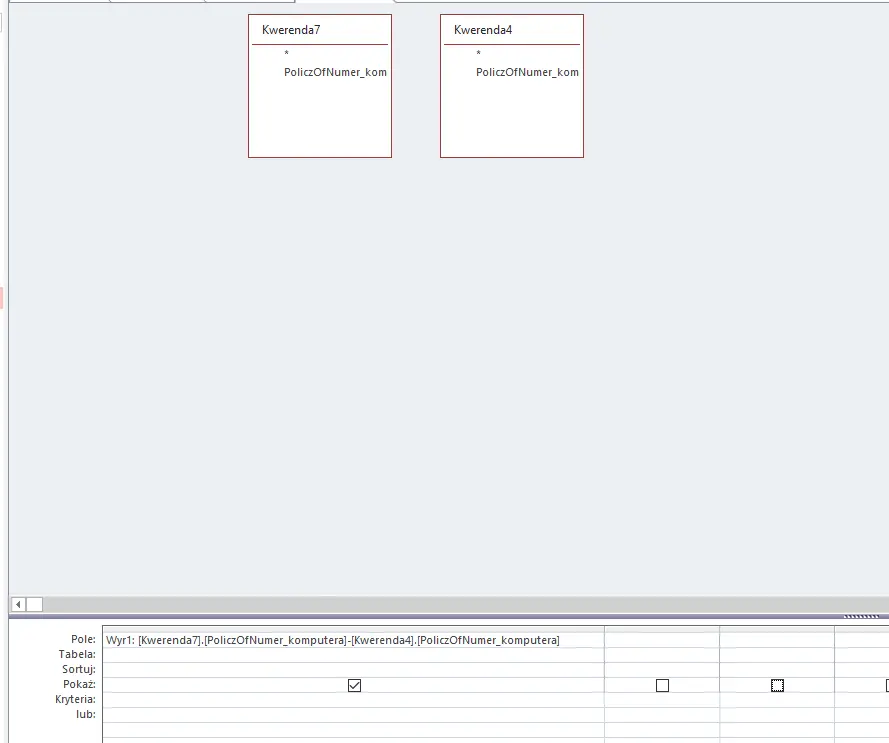
Ostatnia, najważniejsza kwerenda będzie miała za zadanie obliczenie różnicy pomiędzy zliczonymi komputerami. Dzięki temu otrzymamy wynik i odpowiedź na pytanie:
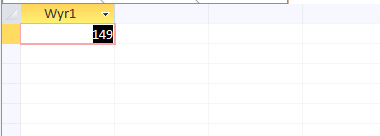
A więc odpowiedź to 149 komputerów.


