
Matura z informatyki 2020 nie należała do najłatwiejszych — ze względu na trudność samych zadań, ale też i problemów związanych z pandemią koronawirusa. Maturę z informatyki w tym roku zdecydowało się pisać niecałe 3.5% wszystkich zdających. Nic dziwnego, bowiem to rozszerzenie nie należy do najłatwiejszych. Chcąc pomóc maturzystom, przedstawiamy arkusz matury z informatyki 2020 wraz z rozwiązaniami krok po kroku.
Matura z informatyki 2020 arkusz — część pierwsza (teoria)
Część teoretyczna zazwyczaj uchodzi za tą łatwiejszą. Nie mamy w niej jednak dostępu do komputera, który okazałby się bardzo przydatny przy sprawdzaniu algorytmów, jednak nie są to wybitnie trudne zadania i możliwe jest ich wykonanie na kartce (lub dla odważniejszych w pamięci). Pamiętajmy, że do dyspozycji jest również cała pusta strona na końcu, w której możesz zapisywać swoje luźne przeliczenia i pomysły. Przejdźmy zatem do zadań:
Matura z informatyki 2020 odpowiedzi: zadanie 1 — zbiory podobne

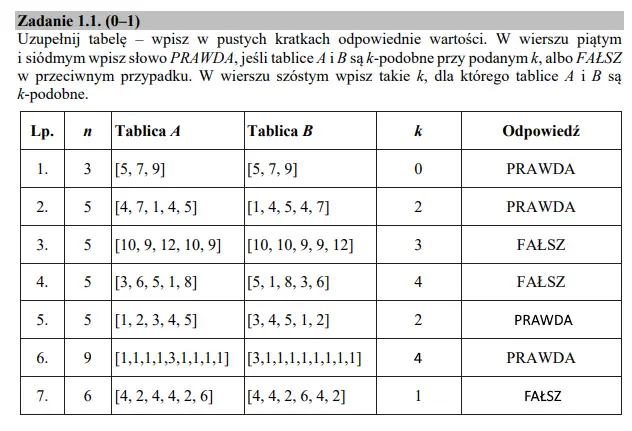
Dwa zbiory o tej samej liczbie elementów całkowitych są k-podobne (k jest mniejsze od wielkości zbiorów), gdy elementy od pierwszego, do k-tego elementu ze zbioru A są takie same jak elementy od (n-k+1)-tego elementu do końca zbioru B. W przypadku, gdy k=0 zbiory są podobne, jeżeli są identyczne. Uwaga: z języków programowania pewnie kojarzysz tablice. Pierwszym elementem tablic jest prawie zawsze element z indeksem 0 (a w zadaniu pierwszy element oznacza 1). Musimy o tym pamiętać w dalszej części tego zadania.
Zadanie 1 — podpunkt 1
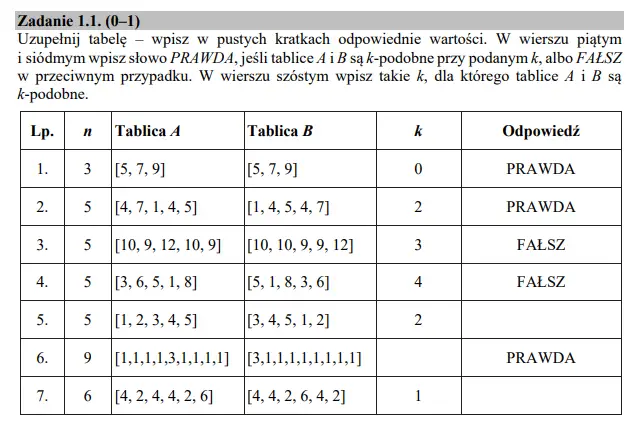
Sprawdzamy zatem, czy podane zbiory spełniają warunki zadania; zaczniemy od pozycji 5. Zapiszmy sobie dane: n=5 i k=2. Musimy zatem sprawdzić, czy elementy od pierwszego do drugiego(k) z tablicy A równają się elementom od czwartego(n-k+1=5-2+1) do piątego(n) z tablicy B. Tablica A={1, 2}, tablica B={1,2}. Elementy się zgadzają. Musimy jeszcze sprawdzić drugi warunek: czy elementy od trzeciego(k+1) do piątego(n) z tablicy A równają się elementom od pierwszego do trzeciego(n-k); Tablica A={3,4,5}, tablica B={3,4,5}. Oba warunki zostały spełnione, więc w kratce obok wpisujemy PRAWDA.
Analogicznie wykonujemy zadanie dla wiersza 7.: Tablica A={4}, tablica B={2}; Tablica A={2,4,4,2,6}, tablica B={4,4,2,6,4}. Jak widać oba warunki nie zostały spełnione, więc w okienku obok wpisujemy FAŁSZ.
W wierszu szóstym widnieje PRAWDA. Oznacza więc to, że oba warunki są spełnione. Zauważamy zatem, że skoro od pierwszego do k-tego elementu zbiór A jest równy pewnej części zbioru B, to k nie może być większe niż 4, gdyż wtedy w pierwszym warunku zawierałaby się liczba 3, która zaś jest początkiem zbioru B, co oznacza, że warunek nie byłby spełniony. Sprawdźmy zatem warunki dla k=4: Tablica A={1,1,1,1}, tablica B{1,1,1,1}; Tablica A={3,1,1,1,1}, Tablica B={3,1,1,1,1}; oba warunki są spełnione, więc wpisujemy w okienku 4:
Zadanie 1 — podpunkt 2

Za zadanie mamy napisanie funkcji sprawdzającej k-podobność. Poniżej znajdziesz 3 implementacje w dostępnych na maturze językach programowania:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
#include <iostream> using namespace std; bool czy_k_podobne(int n, int* A, int* B, int k) { for (int i = 0; i < k; i++){ //jezeli jednak k > 0, to sprawdzamy warunki narzucone przez zadanie: if(A[i] != B[i+n-k]){ // sprawdzamy pierwszy wzor A[1..k] = B[n-k+1..n] return false; // gdy cos sie nie bedzie zgadzac, zwroc falsz } } for (int i = 0; i < n-k; i++){ if(A[k+i] != B[i]){ // a nastepnie sprawdzamy wzor drugi A[k+1..n] = B[1..n-k] return false; // gdy cos sie nie bedzie zgadzac, zwroc falsz } } return true; //gdy wszystko OK, zwroc Prawde } int main() { int n = 5; int k = 2; int A[n] = {4,7,1,4,5}; int B[n] = {1,4,5,4,7}; // przykladowe dane z zadania cout << czy_k_podobne(n, A, B, k)<< endl; return 0; } |
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
package matura; import java.io.IOException; public class Main { static boolean czy_k_podobne(int n, int[] A, int[] B, int k) { for (int i = 0; i < k; i++) { //jezeli jednak k > 0, to sprawdzamy warunki narzucone przez zadanie: if (A[i] != B[i + n - k]) { // sprawdzamy pierwszy wzor A[1..k] = B[n-k+1..n] return false; // gdy cos sie nie bedzie zgadzac, zwroc falsz } } for (int i = 0; i < n - k; i++) { if (A[k + i] != B[i]) { // a nastepnie sprawdzamy wzor drugi A[k+1..n] = B[1..n-k] return false; // gdy cos sie nie bedzie zgadzac, zwroc falsz } } return true; //gdy wszystko OK, zwroc Prawde } public static void main(String[] args) throws IOException { int n = 5; int k = 2; int[] A = {4,7,1,4,5}; int[] B = {1,4,5,4,7}; // przykladowe dane z zadania System.out.println(czy_k_podobne(n, A, B, k)); //a następnie drukujemy jej wynik w konsoli } } |
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
def czy_k_podobne(n, A, B, k): #tworzymy metode sprawdzajaca k podobnosc for i in range(k): if A[i] != B[i+n-k]: #sprawdzamy pierwszy wzor A[1..k] = B[n-k+1..n] return False #gdy cos sie nie bedzie zgadzac, zwroc falsz for i in range(n-k): if A[k+i] != B[i]: #a nastepnie sprawdzamy wzor drugi A[k+1..n] = B[1..n-k] return False #gdy cos sie nie bedzie zgadzac, zwroc falsz return True #gdy wszystko OK, zwroc Prawde tablica1 = [4,7,1,4,5] #tworzymy zmienne tablica2 = [1,4,5,4,7] #z danymi wielkosc = 5 #z przykładu podobnosc = 2 #podanego przez CKE czyPodobne = czy_k_podobne(wielkosc, tablica1, tablica2, podobnosc) #wywołujemy naszą funkcję print(str(czyPodobne)) #a następnie drukujemy jej wynik w konsoli |
Zwróć uwagę, że trzeba wziąć pod uwagę indeksowanie zaczynające się od 0, więc zniknęły jedynki z niektórych wzorów.
Zadanie 1 — podpunkt 3

Tym razem musimy napisać funkcję, która sprawdzi, czy istnieje jakikolwiek k, dla którego zbiory są podobne. Wykorzystamy do tego funkcję z poprzedniego podpunktu i fakt, że k należy do przedziału <0,n):
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
#include <iostream> using namespace std; bool czy_k_podobne(int n, int* A, int* B, int k) { if(k==0){ //jezeli liczba k jest rowna zero for(int i = 0; i < n; i++){ //sprawdzmy czy zbiory sa identyczne if (A[i] != B[i]){ // jezeli nie return false; // zwroc falsz } } return true; // w przeciwnym wypadku zwroc true } for (int i = 0; i < k; i++){ //jezeli jednak k > 0, to sprawdzamy warunki narzucone przez zadanie: if(A[i] != B[i+n-k]){ // sprawdzamy pierwszy wzor A[1..k] = B[n-k+1..n] return false; // gdy cos sie nie bedzie zgadzac, zwroc falsz } } for (int i = 0; i < k-n; i++){ if(A[k+i] != B[i]){ // a nastepnie sprawdzamy wzor drugi A[k+1..n] = B[1..n-k] return false; // gdy cos sie nie bedzie zgadzac, zwroc falsz } } return true; //gdy wszystko OK, zwroc Prawde } bool czy_podobne(int n, int* A, int* B) { for(int k=0; k < n; k++){ // skoro k to nieujemne liczba calkowita mniejsza od n, to aby znalezc taka k, ktora spelni wymagania wystarczy przeiterowac przez liczby mniejsze od n if(czy_k_podobne(n, A, B, k)){ // jezeli dana k spelnila rownanie return true; // zwroc prawde } } return false; //jezeli dla zadnego k nie znalezniono podobienstwa, zwroc falsz } int main() { int n = 5; int k = 2; int A[n] = {4,7,1,4,5}; int B[n] = {1,4,5,4,7}; // przykladowe dane z zadania cout << czy_podobne(n, A, B)<< endl; return 0; } |
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
package matura; import java.io.IOException; public class Main { static boolean czy_k_podobne(int n, int[] A, int[] B, int k){ for (int i = 0; i < k; i++){ //jezeli jednak k > 0, to sprawdzamy warunki narzucone przez zadanie: if(A[i] != B[i+n-k]){ // sprawdzamy pierwszy wzor A[1..k] = B[n-k+1..n] return false; // gdy cos sie nie bedzie zgadzac, zwroc falsz } } for (int i = 0; i < n-k; i++){ if(A[k+i] != B[i]){ // a nastepnie sprawdzamy wzor drugi A[k+1..n] = B[1..n-k] return false; // gdy cos sie nie bedzie zgadzac, zwroc falsz } } return true; //gdy wszystko OK, zwroc Prawde } static boolean czy_podobne(int n, int[] A, int[] B){ for(int k=0; k < n; k++){ // skoro k to nieujemne liczba calkowita mniejsza od n, to aby znalezc taka k, ktora spelni wymagania wystarczy przeiterowac przez liczby mniejsze od n if(czy_k_podobne(n, A, B, k)){ // jezeli dana k spelnila rownanie return true; // zwroc prawde } } return false; //jezeli dla zadnego k nie znalezniono podobienstwa, zwroc falsz } public static void main(String[] args) throws IOException { int n = 5; int[] A = {4,7,1,4,5}; int[] B = {1,4,5,4,7}; // przykladowe dane z zadania System.out.println(czy_podobne(n, A, B)); //a następnie drukujemy jej wynik w konsoli } } |
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def czy_k_podobne(n, A, B, k): #tworzymy metode sprawdzajaca k podobnosc for i in range(k): if A[i] != B[i+n-k]: #sprawdzamy pierwszy wzor A[1..k] = B[n-k+1..n] return False #gdy cos sie nie bedzie zgadzac, zwroc falsz for i in range(n-k): if A[k+i] != B[i]: #a nastepnie sprawdzamy wzor drugi A[k+1..n] = B[1..n-k] return False #gdy cos sie nie bedzie zgadzac, zwroc falsz return True #gdy wszystko OK, zwroc Prawde def czy_podobne(n, A, B): for k in range(n): #skoro k to nieujemne liczba calkowita mniejsza od n, to aby znalezc taka k, ktora spelni wymagania wystarczy przeiterowac przez liczby mniejsze od n if czy_k_podobne(n, A, B, k): #jezeli dana k spelnila rownanie return True #zwroc prawde return False #jezeli dla zadnego k nie znalezniono podobienstwa, zwroc falsz tablica1 = [4,7,1,4,5] #tworzymy zmienne tablica2 = [1,4,5,4,7] #z danymi wielkosc = 5 #z przykładu czyPodobne = czy_podobne(wielkosc, tablica1, tablica2) #wywołujemy naszą funkcję print(str(czyPodobne)) #a następnie drukujemy jej wynik w konsoli |
Matura z informatyki 2020 rozwiązania: zadanie 2 – symetryczny ciąg

Przedstawię najpierw podany algorytm jako schemat blokowy:
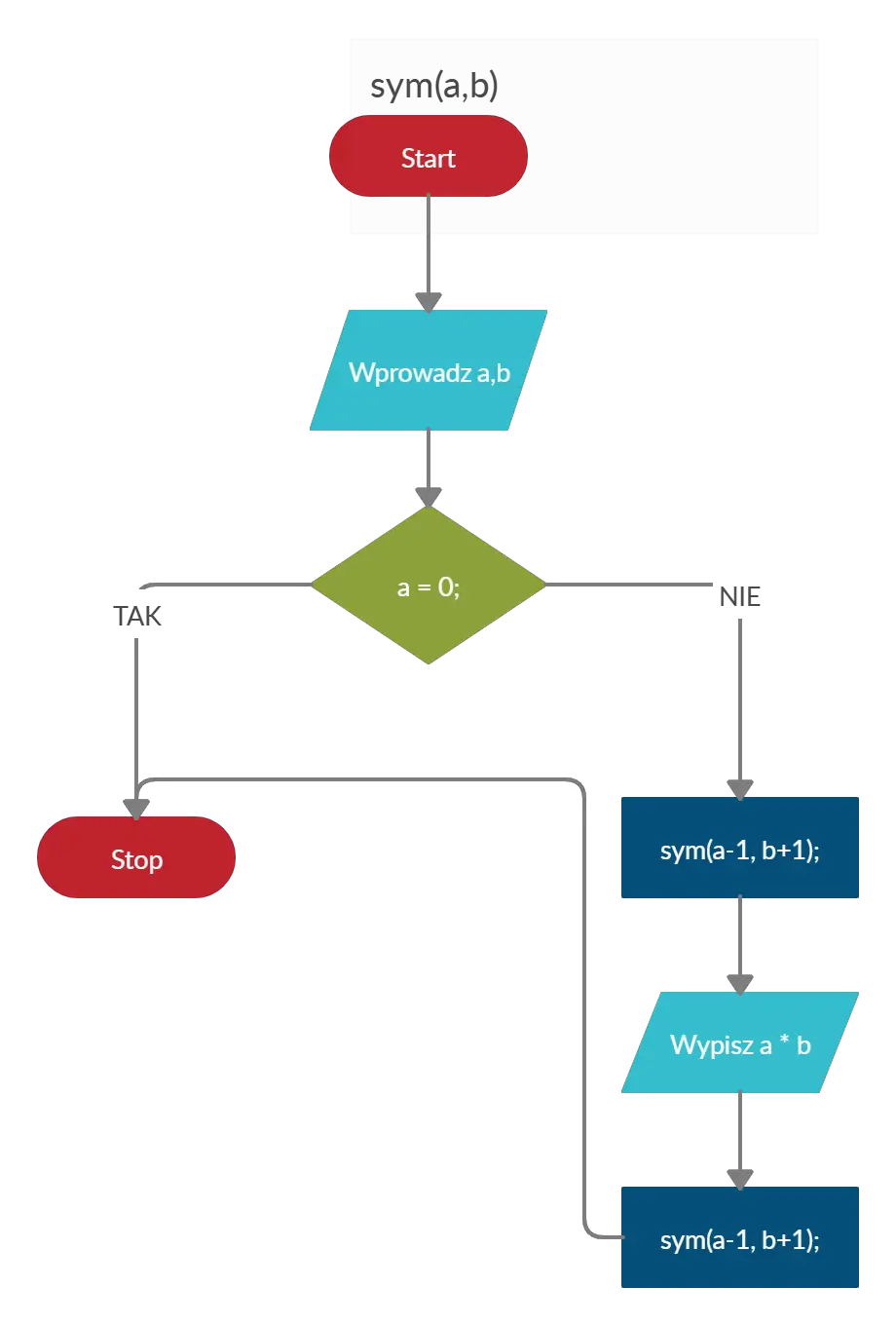
Zauważamy w nim podwójną rekurencję (jeżeli nie wiesz co to, sprawdź tutaj). Jak sama nazwa zadania podpowiada: jego zadaniem jest wypisanie symetrycznego ciągu liczb całkowitych. Zwróć również uwagę, że ilość wywołań funkcji jest zależna od liczby a (to ona warunkuje zatrzymanie rekurencji). Jedno wywołanie funkcji dla a>0, spowoduje dwa następne wywołania, co po krótkiej kalkulacji daje nam (2^a) — 1 wypisań.
Zadanie 2 — podpunkt 1
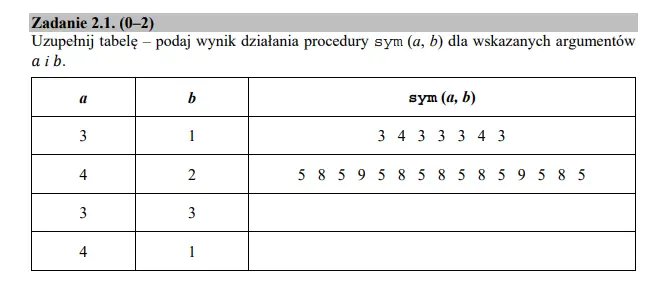
Aby wykonać to zadanie musimy po prostu prześledzić działanie algorytmu dla podanych a i b. Dobrze jest rozpisać sobie drzewo wywołań, pamiętając przy tym, że jedno rekurencyjne wywołanie tworzy nową gałąź, dopóki nie napotka ona warunku stopującego. Poprawnie uzupełniona tabela powinna wyglądać tak:
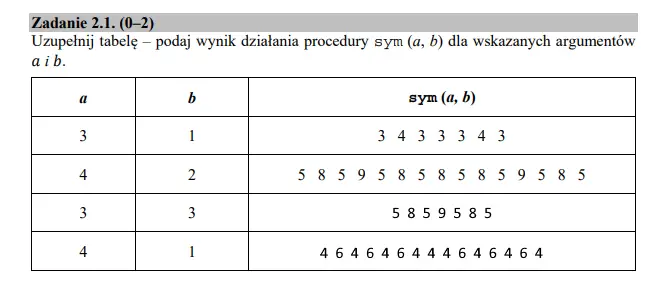
Zadanie 2 — podpunkt 2

Przy analizie algorytmu zauważyliśmy już zależność liczby wypisań, od liczby a. Korzystając więc ze wzoru, który wyprowadziliśmy sobie powyżej, możemy rozwiązać ten podpunkt:

Matura z informatyki 2020 odpowiedzi: zadanie 3 – zadanie zamknięte
Tak jak co roku, w zadaniu zamkniętym będziemy musieli wykazać się przede wszystkim wiedzą teoretyczną. Za drobne pomyłki tutaj trzeba niestety słono zapłacić — jeden błąd = utrata całego podpunktu.
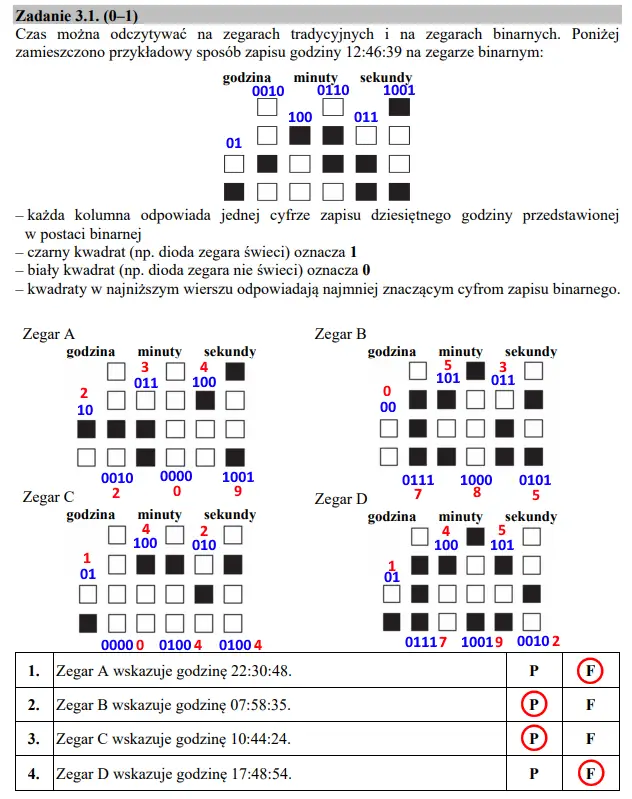
Zadanie 3 — podpunkt 1

Zegarki binarne działają tak, jak podpowiedziano nam w treści podpunktu: niższe lampki oznaczają ostatnie cyfry z liczby w zapisie dwójkowym. Wystarczy zatem zapisać wartość binarną dla każdej „wskazówki”, a następnie zamienić ją na liczbę dziesiętną, dzięki czemu możemy sprawdzić godzinę. Na poniższym zrzucie na niebiesko zapisałem liczby w postaci binarnej, zaś na czerwono te same liczby w postaci dziesiętnej. Niżej zaznaczone są również prawidłowe odpowiedzi:
Zadanie 3 — podpunkt 2

Przeanalizujmy ten algorytm na schemacie blokowym:
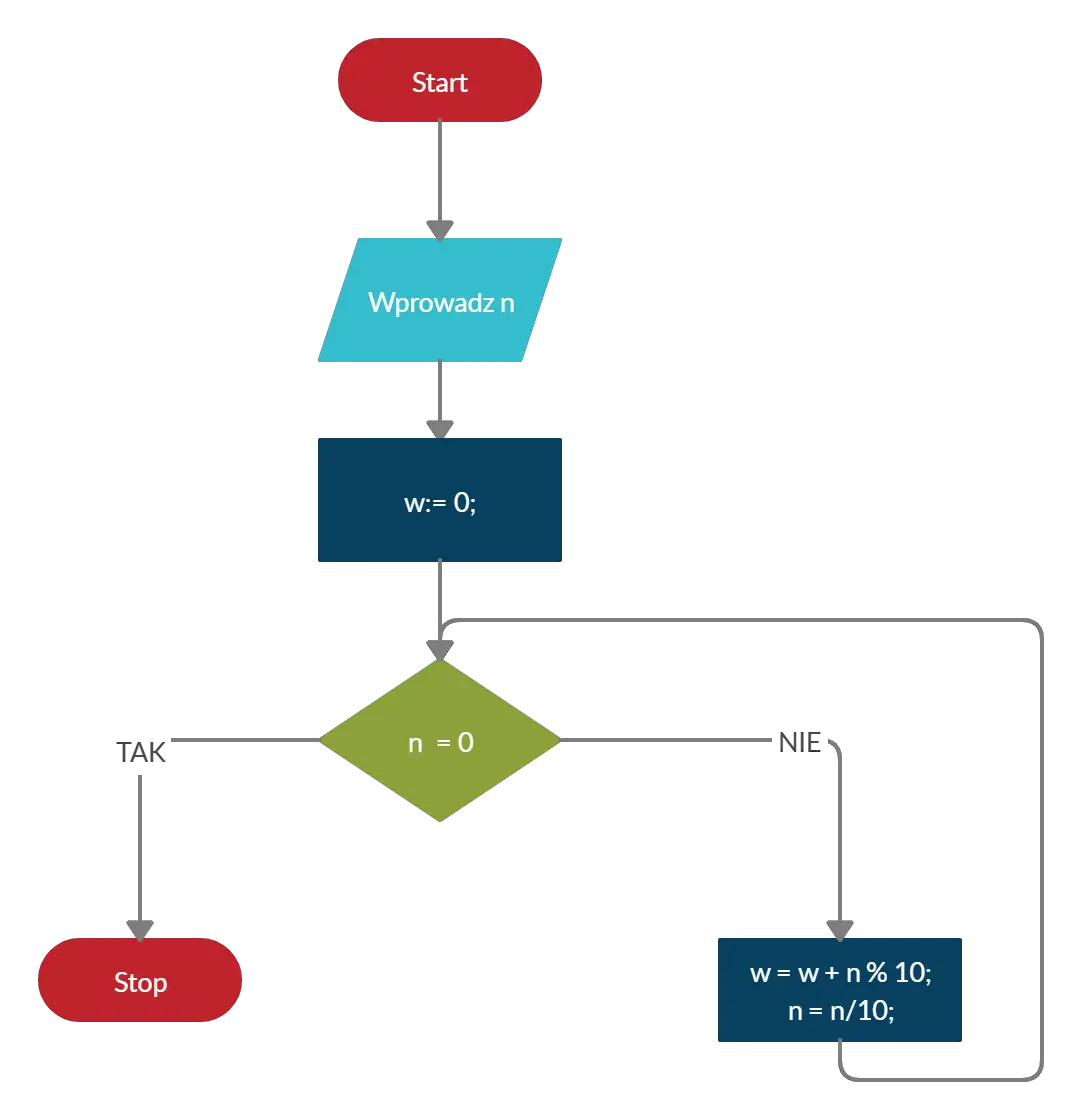
Podobny algorytm wykorzystywaliśmy na poprzednich maturach: wypisuje on pojedyncze cyfry z podanej liczby ( Uwaga: wypisuje je w kolejności odwrotnej, czyli od prawej do lewej). Algorytm ten dodatkowo zlicza sumę poszczególnych cyfr. Mając na uwadze powyższe, nie powinno być problemu z rozwiązaniem tego podpunktu; prawidłowe odpowiedzi widoczne są poniżej:

Zadanie 3 — podpunkt 3
Do tego podpunktu wymagana jest wiedza z sieci i przeliczania adresów, które dosyć rzadko pojawiają się na maturze z informatyki. Odpowiedzi możesz sprawdzić na poniższym obrazku:

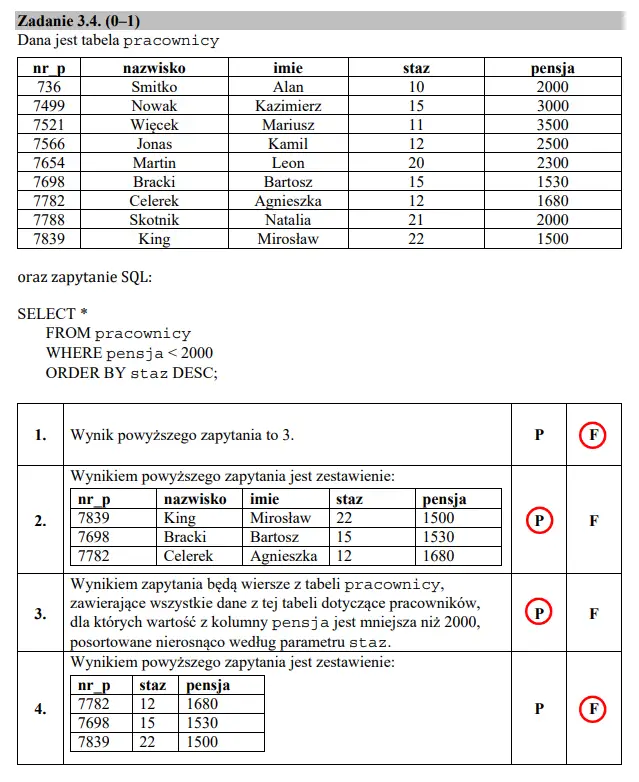
Zadanie 3 — podpunkt 4
W poniższym podpunkcie wymagana jest wiedza z języka SQL. O tyle łatwo jest, że odpowiedzi się „zazębiają”, co wyklucza dwie pozostałe. Na zrzucie zaznaczyłem poprawne odpowiedzi:

Matura z informatyki 2020 — część druga (praktyka)
Za nami pierwsza część matury z informatyki. W części praktycznej do dyspozycji masz już komputer z wybranym przez siebie systemem operacyjnym i środowiskiem programistycznym. Dostępne są również pozostałe narzędzia informatyczne jak np. Access czy Excel. Przejdźmy zatem do rozwiązywania kolejnych zadań:
Matura z informatyki 2020 arkusz: zadanie 4 — liczby i wyrazy

W następnych podpunktach użyjemy programów napisanych w 3 językach, które możesz użyć na maturze – Javie, C++ oraz Pythonie. Odczytamy w nich każdy wiersz z pliku tekstowego pary.txt, a następnie oddzielimy liczbę od wyrazu. Podam zatem kody źródłowe programów, na których będziemy bazować, wprowadzając odpowiednie modyfikacje:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#include <fstream> #include <string> #include <iostream> using namespace std; int main() { string line; //aktualny wiersz string word; //slowo z wiersza int num; // liczba z wiersza ifstream file("pary.txt"); //inicjalizacja pliku; wymagana sciezka do pliku if(file.is_open()){ //jezeli uda sie otworzyc plik while (getline (file,line)){ //dopoki sa jeszcze wiersze, odczytuj je do zmiennej num = stoi(line.substr(0, line.find(" "))); //znajdujemy pozycje spacji w wierszu, a nastepnie podlug niej wybieramy liczbe z wiersza(jako string) i zamieniamy ja na int word = line.substr(line.find(" ")+1, line.length()-1); //znajdujemy pozycje spacji w wierszu, a nastepnie podlug niej wybieramy slowo z wiersza cout << num << " " << word << endl; //sprawdzamy cout << line << endl; // prawidlowosc odczytu } file.close(); // zamykamy plik } return 0; } |
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
package matura; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; public class Main { public static void main(String[] args) throws IOException { File f = new File("pary.txt"); //tworzymy zmienna plikowa if (!f.exists()) { //przed rozpoczeciem pracy z plikiem nalezy sprawdzic, czy w ogole istnieje System.out.println("Podany plik nie istnieje."); return; } BufferedReader br = new BufferedReader(new FileReader(f)); //tworzymy instancje BufferedReadera if (br.ready()) { //jezeli BR jest gotowy do oczytu String line; // tworzymy zmienna przechowujaca aktualny wiersz while ((line = br.readLine()) != null) { //zczytujemy kazdy wiersz System.out.println(line); //drukujemy zawartosc pliku } } br.close(); // na koniec zamykamy plik } } |
Python
|
1 2 3 4 5 |
file = open("pary.txt", "r") #jezeli plik nie bedzie istnial, to program zwroc blad lines = file.read().splitlines() #pozbywamy sie znakow nowego wiersza file.close() #zamykamy plik for line in lines: print(line) #drukujemy zawartosc pliku |
Zadanie 4 — podpunkt 1

W programie potrzebna nam będzie po pierwsze funkcja sprawdzająca czy liczba jest pierwsza; wykorzystamy przy tym fakt, że gdy liczba n jest pierwsza, to dla każdej liczby całkowitej mniejszej od pierwiastka kwadratowego n i większej od 1 nie istnieje liczba, która by była dzielnikiem liczby n. Następnie stworzymy funkcję sprawdzającą hipotezę Goldbacha, a następnie wypisującą rozwiązanie. Szczegóły znajdziesz w komentarzach w poniższym, działającym kodzie źródłowym programu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
#include <fstream> #include <string> #include <iostream> #include <math.h> using namespace std; bool czyPierwsza(int n) { int s = sqrt(n); // liczba n jest pierwsza for (int i = 2; i < s; i++){ // sprawdzamy wiec kazda liczbe if(n % i == 0){ //jezeli ktorakolwiek bedzie dzielnikiem liczby n return false; // to n nie jest pierwsza } } return true; //jezeli zadna z liczb nim nie bedzie, to n jest liczba pierwsza } void goldbach(int n) { if(n % 2 != 0){ // jezeli liczba nie jest parzysta return; // przerwij dzialanie procedury } int num1 = 0; // zmienna pomocnicza dla mniejszej liczby int num2 = 0; // zmienna pomocnicza dla wiekszej liczby for(int i = 3; i <= n; i++){ // iterujemy przez wszystkie dodatnie calkowite liczby mniejsze od n int r = n - i; // liczymy roznice pomiedzy n a iterowana liczba if((czyPierwsza(i) && czyPierwsza(r)) && (num2 - num1 <= r - i)){ // jezeli zarowno iterowana liczba, jak i roznica sa liczbami pierwszym ORAZ ich roznica jest wieksza niz przechowanych liczb num2 = r; // zapisujemy obie liczby num1 = i; } } cout << n << " " << num1 << " " << num2 << endl; // drukujemy rozwiazanie dla n } int main() { string line; //aktualny wiersz int num; // liczba z wiersza ifstream file("pary.txt"); //inicjalizacja pliku; wymagana sciezka do pliku if(file.is_open()){ //jezeli uda sie otworzyc plik while (getline (file,line)){ //dopoki sa jeszcze wiersze, odczytuj je do zmiennej num = stoi(line.substr(0, line.find(" "))); //znajdujemy pozycje spacji w wierszu, a nastepnie podlug niej wybieramy liczbe z wiersza(jako string) i zamieniamy ja na int goldbach(num); // wykorzystujemy nasza funkcje } file.close(); // zamykamy plik } return 0; } |
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
package matura; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; public class Main { static boolean czyPierwsza(int n) { int s = (int) Math.sqrt(n); // liczba n jest pierwsza for (int i = 2; i < s; i++) { // sprawdzamy wiec kazda liczbe if (n % i == 0) { //jezeli ktorakolwiek bedzie dzielnikiem liczby n return false; // to n nie jest pierwsza } } return true; //jezeli zadna z liczb nim nie bedzie, to n jest liczba pierwsza } static void goldbach(int n) { if (n % 2 != 0) { // jezeli liczba nie jest parzysta return; // przerwij dzialanie procedury } int num1 = 0; // zmienna pomocnicza dla mniejszej liczby int num2 = 0; // zmienna pomocnicza dla wiekszej liczby for (int i = 3; i <= n; i++) { // iterujemy przez wszystkie dodatnie calkowite liczby mniejsze od n int r = n - i; // liczymy roznice pomiedzy n a iterowana liczba if ((czyPierwsza(i) && czyPierwsza(r)) && (num2 - num1 <= r - i)) { // jezeli zarowno iterowana liczba, jak i roznica sa liczbami pierwszym ORAZ ich roznica jest wieksza niz przechowanych liczb num2 = r; // zapisujemy obie liczby num1 = i; } } System.out.println(n + " " + num1 + " " + num2); // drukujemy rozwiazanie dla n } public static void main(String[] args) throws IOException { File f = new File("pary.txt"); //tworzymy zmienna plikowa if (!f.exists()) { //przed rozpoczeciem pracy z plikiem nalezy sprawdzic, czy w ogole istnieje System.out.println("Podany plik nie istnieje."); return; } BufferedReader br = new BufferedReader(new FileReader(f)); //tworzymy instancje BufferedReadera if (br.ready()) { //jezeli BR jest gotowy do oczytu String line; // tworzymy zmienna przechowujaca aktualny wiersz while ((line = br.readLine()) != null) { //zczytujemy kazdy wiersz int num; num = Integer.parseInt((line.split(" ")[0])); //dzielimy wiersz spacja, po czym wybieramy pierwszy element - liczbe goldbach(num); // wykorzystujemy nasza funkcje } } br.close(); // na koniec zamykamy plik } } |
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import math def czyPierwsza(n): s = int(math.sqrt(n)) for i in range(2, s+1): if n % i == 0: return False return True def goldbach(n): if n % 2 != 0: return num1 = 0 num2 = 0 for i in range(3, n+1): r = n-i if r % 2 == 0 or i % 2 == 0: continue if not czyPierwsza(r) or not czyPierwsza(i): continue if num2-num1 <= r - i: num2 = r num1 = i print (str(n) + " " + str(num1) + " " + str(num2)) file = open("pary.txt", "r") #jezeli plik nie bedzie istnial, to program zwroc blad lines = file.read().splitlines() #pozbywamy sie znakow nowego wiersza file.close() #zamykamy plik for line in lines: num = int(line.split(" ")[0]) goldbach(num) |
Program wydrukuje łącznie 28 odpowiedzi zgodnymi z wymogami zadania. Zauważ, że wykorzystałem tutaj dodatkową dyrektywę math.h w języku C++ oraz import math w Pythonie. Pamiętaj, że możesz sprawdzić działanie programu poprzez przepuszczenie przez niego pliku przyklad.txt i porównanie odpowiedzi z tymi podanymi w zadaniu.
Zadanie 4 – podpunkt 2

Tym razem operować będziemy na wyrazach. Przeiterujemy więc przez jego zawartość, sprawdzając długość najdłuższego ciągu i zapisując go jako string(bo po co tworzyć specjalnie tablicę znaków, skoro string jest taką tablicą). Na koniec wyrzucimy do konsoli najdłuższy ciąg znaków z danego wyrazu i przejdziemy do następnego. Wszystko opisane w kodach źródłowych poniżej:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
#include <fstream> #include <string> #include <iostream> using namespace std; int main() { string line; //aktualny wiersz string word; //slowo z wiersza ifstream file("pary.txt"); //inicjalizacja pliku; wymagana sciezka do pliku if(file.is_open()){ //jezeli uda sie otworzyc plik while (getline (file,line)){ //dopoki sa jeszcze wiersze, odczytuj je do zmiennej word = line.substr(line.find(" ")+1, line.length()-1); //znajdujemy pozycje spacji w wierszu, a nastepnie podlug niej wybieramy slowo z wiersza string longest = ""; // zmienna przechowujaca najdluzszy ciag znakow string current = ""; // zmienna przechowujaca aktualnie najdluzszy caig znakow w petli for (int i = 0; i < word.length();i++) // iterujemy przez wyraz { if(current.length() == 0 || current[0] == word[i]){ // jezeli aktualne slowo jest puste LUB iterowany znak ze slowa jest taki sam jak ten przechowany current += word[i]; // dodaj go do aktualnego ciagu znakow } else // w przeciwnym wypadku { if(current.length() > longest.length()){ //sprawdz, czy aktualny ciag nie jest dluzszy niz ten zapisany longest = current; // jezeli tak to go zmien } current = ""; // resetujemy wartosc current += word[i]; // zapisujemy aktualna literke } } if(current.length() > longest.length()){ //sprawdz, czy aktualny ciag nie jest dluzszy niz ten zapisany longest = current; // jezeli tak to go zmien } if(longest.length() == 0){ //w przypadku, gdy caly wyraz skladal sie z tej samej litery(wtedy nie przypisany zostanie zaden ciag do longest) longest = current; // nalezy go przypisac } cout << longest << " " << longest.length() <<endl; //drukujemy wynik dla danego wiersza } file.close(); // zamykamy plik } return 0; } |
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
package matura; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; public class Main { public static void main(String[] args) throws IOException { File f = new File("pary.txt"); //tworzymy zmienna plikowa if (!f.exists()) { //przed rozpoczeciem pracy z plikiem nalezy sprawdzic, czy w ogole istnieje System.out.println("Podany plik nie istnieje."); return; } BufferedReader br = new BufferedReader(new FileReader(f)); //tworzymy instancje BufferedReadera if (br.ready()) { //jezeli BR jest gotowy do oczytu String line; // tworzymy zmienna przechowujaca aktualny wiersz String word; //slowo z wiersza while ((line = br.readLine()) != null) { //zczytujemy kazdy wiersz word = line.split(" ")[1]; //dzielimy wiersz spacja, a nastepnie pobieramy drugi element - slowo String longest = ""; // zmienna przechowujaca najdluzszy ciag znakow String current = ""; // zmienna przechowujaca aktualnie najdluzszy caig znakow w petli for (int i = 0; i < word.length(); i++) // iterujemy przez wyraz { if (current.length() == 0 || current.charAt(0) == word.charAt(i)) { // jezeli aktualne slowo jest puste LUB iterowany znak ze slowa jest taki sam jak ten przechowany current += word.charAt(i); // dodaj go do aktualnego ciagu znakow } else // w przeciwnym wypadku { if (current.length() > longest.length()) { //sprawdz, czy aktualny ciag nie jest dluzszy niz ten zapisany longest = current; // jezeli tak to go zmien } current = ""; // resetujemy wartosc current += word.charAt(i); // zapisujemy aktualna literke } } if (current.length() > longest.length()) { //sprawdz, czy aktualny ciag nie jest dluzszy niz ten zapisany longest = current; // jezeli tak to go zmien } if (longest.length() == 0) { //w przypadku, gdy caly wyraz skladal sie z tej samej litery(wtedy nie przypisany zostanie zaden ciag do longest) longest = current; // nalezy go przypisac } System.out.println(longest + " " + longest.length()); //drukujemy wynik dla danego wiersza } } br.close(); // na koniec zamykamy plik } } |
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
file = open("pary.txt", "r") #jezeli plik nie bedzie istnial, to program zwroc blad lines = file.read().splitlines() #pozbywamy sie znakow nowego wiersza file.close() #zamykamy plik word = "" #slowo z wiersza for line in lines: #zczytujemy kazdy wiersz word = line.split(" ")[1] #dzielimy wiersz spacja, a nastepnie pobieramy drugi element - slowo longest = "" #zmienna przechowujaca najdluzszy ciag znakow current = "" #zmienna przechowujaca aktualnie najdluzszy caig znakow w petli for i in range(len(word)): #iterujemy przez wyraz if len(current) == 0 or current[0] == word[i]: #jezeli aktualne slowo jest puste LUB iterowany znak ze slowa jest taki sam jak ten przechowany current += word[i] #dodaj go do aktualnego ciagu znakow else: #w przeciwnym wypadku if len(current) > len(longest): #sprawdz, czy aktualny ciag nie jest dluzszy niz ten zapisany longest = current #jezeli tak to go zmien current = "" #resetujemy wartosc current += word[i] #zapisujemy aktualna literke if len(current) > len(longest): #sprawdz, czy aktualny ciag nie jest dluzszy niz ten zapisany longest = current #jezeli tak to go zmien if len(longest) == 0: #w przypadku, gdy caly wyraz skladal sie z tej samej litery(wtedy nie przypisany zostanie zaden ciag do longest) longest = current #nalezy go przypisac print(longest + " " + str(len(longest))) #drukujemy wynik dla danego wiersza |
Zadanie 4 – podpunkt 3

Tutaj operujemy już na całej parze, ale i tak będzie wymagana jej separacja. Stworzymy funkcję sprawdzającą, czy dana para jest większa od poprzedniej (najpierw sprawdzimy liczbę, a jeżeli są równe to porównamy ciągi znaków). Następnie wrzucimy wszystkie pary w vector w C++ (wymagana dodatkowa dyrektywa), ArrayList w Javie(wymagany dodatkowy import) i w tablicę w Pythonie(tu, na szczęście, nic dodatkowego nie jest wymagane :)), a następnie znajdziemy w nich najmniejszą parę.
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
#include <fstream> #include <string> #include <iostream> #include <vector> using namespace std; bool czyMniejszy(string s1, string s2) { int num1 = stoi(s1.substr(0, s1.find(" "))); //wybieramy liczbe z pierwszej pary string word1 = s1.substr(s1.find(" ")+1, s1.length()-1); //wybieramy slowo z pierwszej pary int num2 = stoi(s2.substr(0, s2.find(" "))); //wybieramy liczbe z pierwszej pary string word2 = s2.substr(s2.find(" ")+1, s2.length()-1); //wybieramy slowo z pierwszej pary if(num2> num1){ // porownujemy najpierw liczby return true; } else if(num1 == num2 && word2>word1){ // jezeli sa rowne to porwonujemy wyrazy return true; } return false; // jezeli w zadnym wypadku wyraz nie byl mniejszy to zwroc falsz } int main() { string line; //aktualny wiersz string word; //slowo z wiersza int num; // liczba z wiersza vector<string> slowa; // zmienna przechowujaca wiersze, w ktorych dlugosc slowa = liczba ifstream file("pary.txt"); //inicjalizacja pliku; wymagana sciezka do pliku if(file.is_open()){ //jezeli uda sie otworzyc plik while (getline (file,line)){ //dopoki sa jeszcze wiersze, odczytuj je do zmiennej num = stoi(line.substr(0, line.find(" "))); //znajdujemy pozycje spacji w wierszu, a nastepnie podlug niej wybieramy liczbe z wiersza(jako string) i zamieniamy ja na int word = line.substr(line.find(" ")+1, line.length()-1); //znajdujemy pozycje spacji w wierszu, a nastepnie podlug niej wybieramy slowo z wiersza if(num == word.length()){ // jezeli dlugosc slowa = liczba slowa.push_back(line); //dodaj ja do zbioru } } file.close(); // zamykamy plik } string para = slowa[0]; //zmienna przechowujaca najkrotsza pare for (int i = 1; i < slowa.size(); i++){ // iterujemy przez zapisane pary if(czyMniejszy(slowa[i], para)){ // i sprawdzamy ktory jest najmniejszy para = slowa[i]; // i go zapisujemy } } cout << para << endl; // drukujemy wynik return 0; } |
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
package matura; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; import java.util.ArrayList; public class Main { static boolean czyMniejszy(String s1, String s2) { int num1 = Integer.parseInt(s1.split(" ")[0]); //wybieramy liczbe z pierwszej pary String word1 = s1.split(" ")[1]; //wybieramy slowo z pierwszej pary int num2 = Integer.parseInt(s2.split(" ")[0]); //wybieramy liczbe z pierwszej pary String word2 = s2.split(" ")[1]; //wybieramy slowo z pierwszej pary if (num2 > num1) { // porownujemy najpierw liczby return true; } else if (num1 == num2 && word2.compareTo(word1) > 0) { // jezeli sa rowne to porwonujemy wyrazy return true; } return false; // jezeli w zadnym wypadku wyraz nie byl mniejszy to zwroc falsz } public static void main(String[] args) throws IOException { File f = new File("pary.txt"); //tworzymy zmienna plikowa if (!f.exists()) { //przed rozpoczeciem pracy z plikiem nalezy sprawdzic, czy w ogole istnieje System.out.println("Podany plik nie istnieje."); return; } BufferedReader br = new BufferedReader(new FileReader(f)); //tworzymy instancje BufferedReadera if (br.ready()) { //jezeli BR jest gotowy do oczytu String line; // tworzymy zmienna przechowujaca aktualny wiersz String word; //slowo z wiersza int num; //liczba z wiersza ArrayList < String > slowa = new ArrayList < String > (); //zmienna przechowujaca wiersze, w ktorych dlugosc slowa = liczba while ((line = br.readLine()) != null) { //zczytujemy kazdy wiersz num = Integer.parseInt(line.split(" ")[0]); //dzielimy wiersz na spacje, nastepnie pobieramy pierwszy element(jako string) i zamieniamy ja na int word = line.split(" ")[1]; //dzielimy wiersz na spacje, nastepnie pobieramy drugi element(jako string) if (word.length() == num) { //jezeli dlugosc slowa = liczba slowa.add(line); //dodaj ja do zbioru } } String para = slowa.get(0); //zmienna przechowujaca najkrotsza pare for (int i = 1; i < slowa.size(); i++) { // iterujemy przez zapisane pary if (czyMniejszy(slowa.get(i), para)) { // i sprawdzamy ktory jest najmniejszy para = slowa.get(i); // i go zapisujemy } } System.out.println(para); //drukujemy wynik } br.close(); // na koniec zamykamy plik } } |
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
def czyMniejszy(wyr1, wyr2): num1 = int(wyr1.split(" ")[0]) num2 = int(wyr2.split(" ")[0]) if num2 > num1: return True word1 = wyr1.split(" ")[1] word2 = wyr2.split(" ")[1] if num1 == num2 and word2 > word1: return True return False file = open("pary.txt", "r") #jezeli plik nie bedzie istnial, to program zwroc blad lines = file.read().splitlines() #pozbywamy sie znakow nowego wiersza file.close() #zamykamy plik num = 0 word = "" words = [] for line in lines: num = int(line.split(" ")[0]) word = line.split(" ")[1] if len(word) == num: words.append(line) najw = words[0] for i in range(1, len(words)): if czyMniejszy(words[i], najw): najw = words[i] print(najw) |
Program drukuje odpowiedź: 3 asd.
Matura z informatyki 2020 rozwiązania: zadanie 5 – języki świata

Jak łatwo zauważyć, poszczególne pliki są oddzielnymi tabelami pewnej bazy, więc do tego zadania wykorzystamy program Microsoft Access. Zanim jednak przystąpimy do rozwiązywania podpunktów, musimy tabele te zaimportować. Przedstawiam krok po kroku jak to zrobić na zrzutach poniżej:
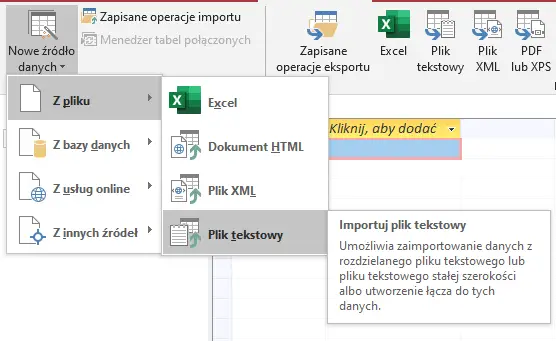
Z zakładki Dane wybieramy Nowe źródło danych>Z pliku>Plik tekstowy.
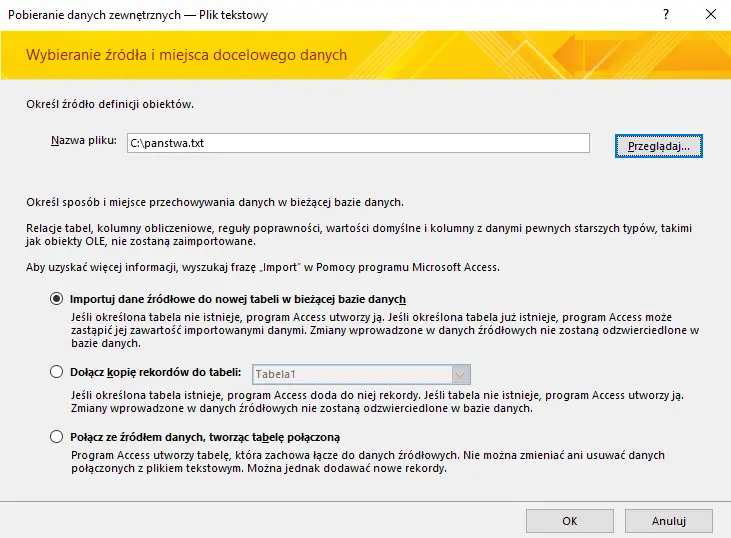
Następnie wybieramy plik tabeli, którą chcemy zaimportować.
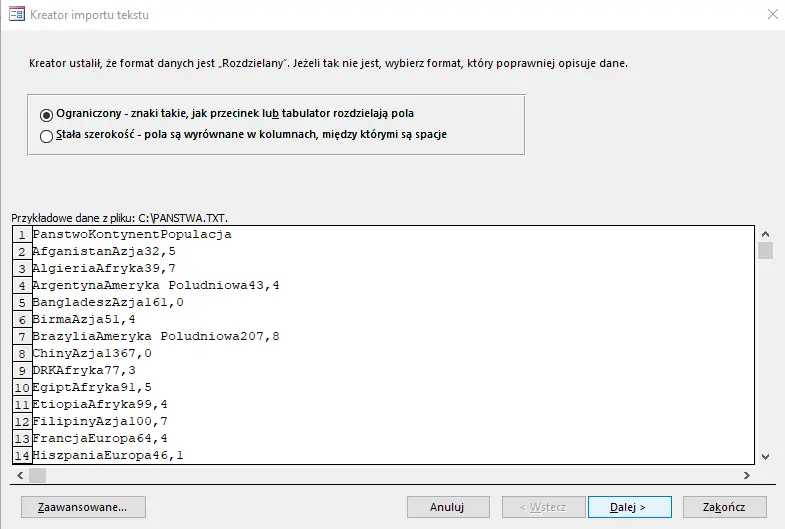
Tutaj bez zmian.
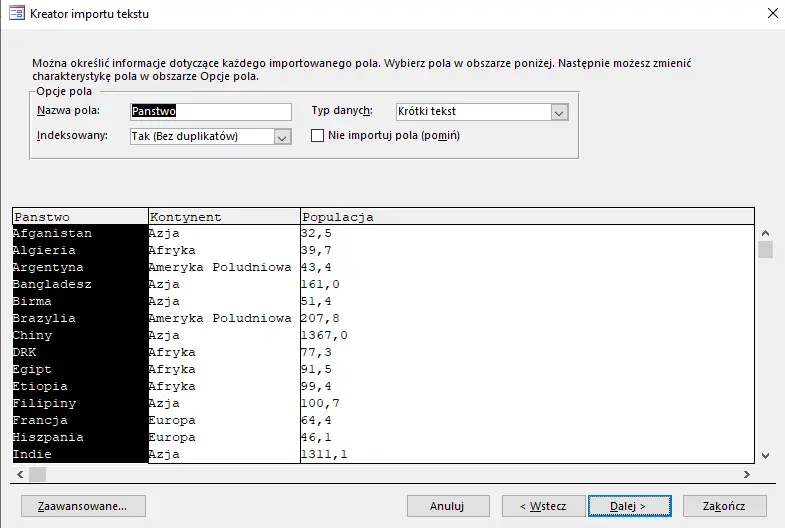
Wybieramy państwo jako indeksowany i unikalny (bez duplikatów).
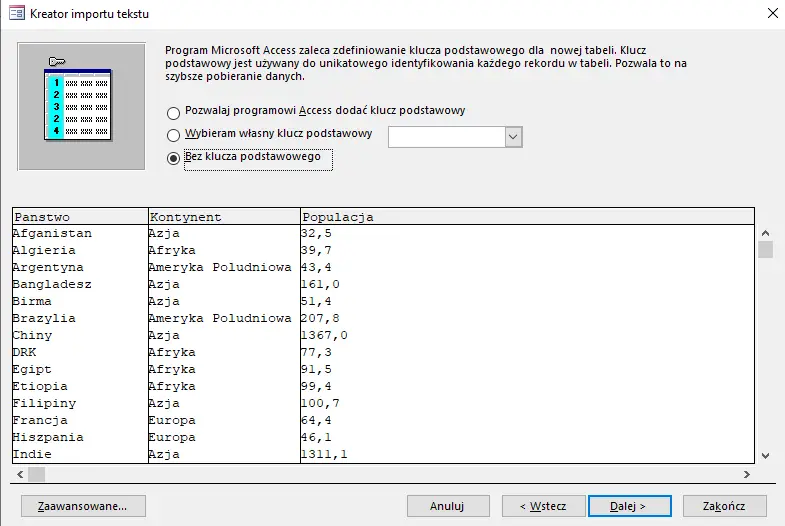
W żadnej z tabel nie dodajemy klucza podstawowego; będziemy operować na nazwach państw i języków. Klikamy Zakończ.
Zaznaczam, że w tabeli Uzytkownicy wybieramy kolumny Jezyk i Panstwo jako indeksowane(duplikaty OK). W tabeli Jezyki kolumna Jezyk powinna być indeksowana bez duplikatów.
Następnie połączymy tabele relacjami tak jak pokazałem na zdjęciu:
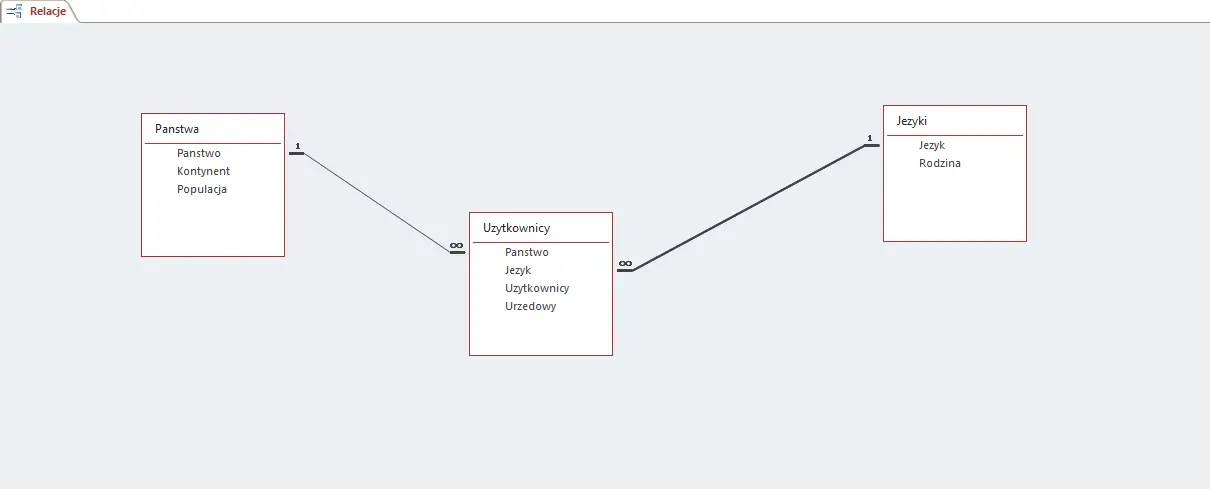
Z tak przygotowaną bazą możemy przystąpić do rozwiązywania podpunktów:
Zadanie 5 — podpunkt 1

W tym podpunkcie wykorzystamy jedną, prostą kwerendę wybierającą rodzinę językową, a następnie korzystając z Sumy(prawy, górny róg w zakładce Projektowanie) i Policz. Projekt kwerendy widoczny jest poniżej:
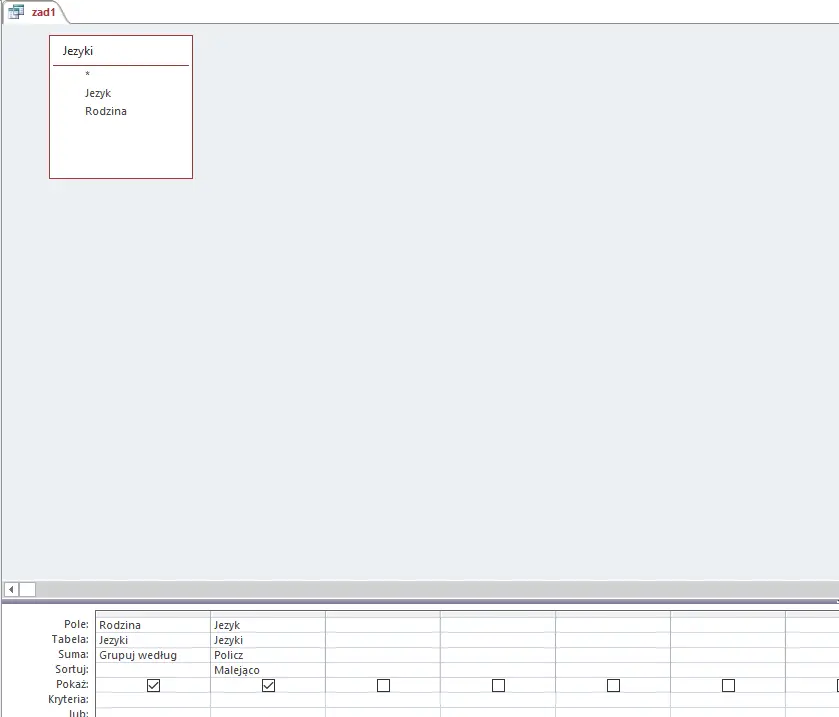
Wynik jej działania (i jednocześnie odpowiedź) powinien wyglądać następująco:
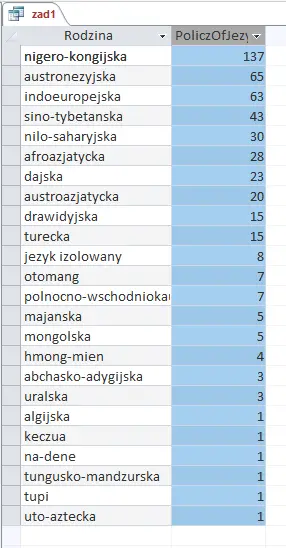
Zadanie 5 — podpunkt 2

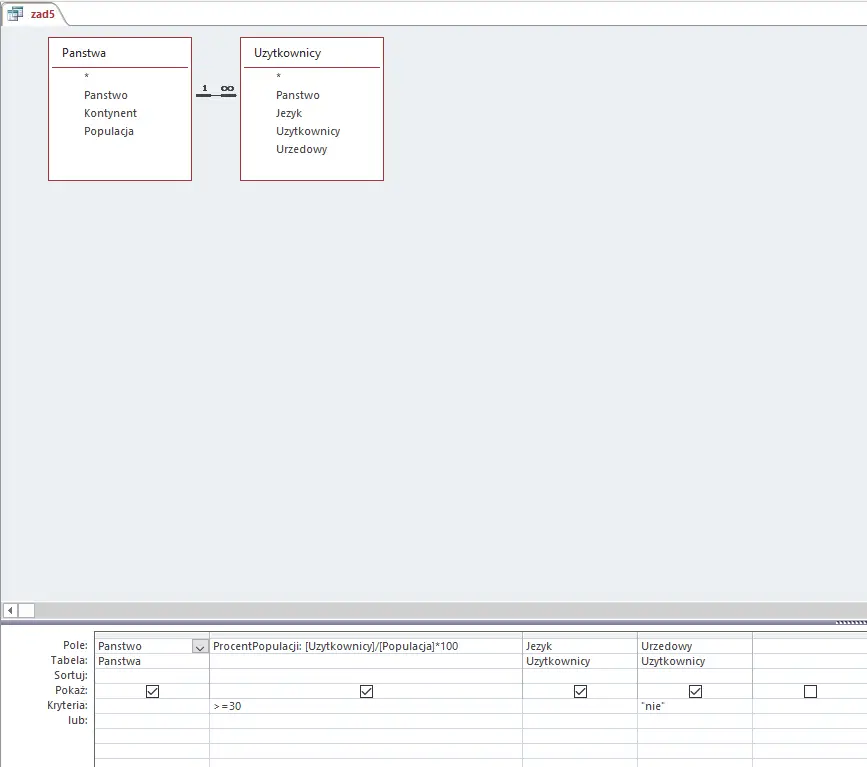
Potrzebna nam będzie pomocnicza kwerenda, która wybierze języki, które są językami urzędowymi w jakimkolwiek kraju. Następnie, w kolejnej kwerendzie, z listy wszystkich języków wystarczy wyłączyć wyniki poprzedniej kwerendy i zliczyć ilość języków. W drugiej kwerendzie wykorzystamy czysty język SQL. Projekt pierwszej kwerendy widoczny jest na poniższym zrzucie:
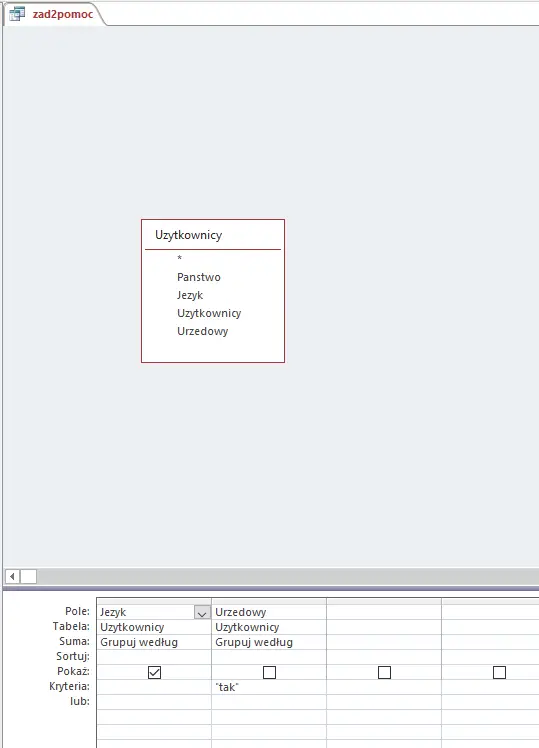
Uwaga: w projekcie kwerendy w języku SQL dodaj słowo DISTINCT tuż po słowie SELECT.
Mając kwerendę pomocniczą, możemy przejść do tworzenia tej właściwej — dającej nam rozwiązanie. Kod SQL następnej kwerendy załączony jest na obrazku:
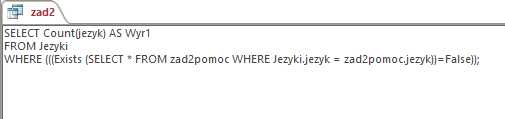
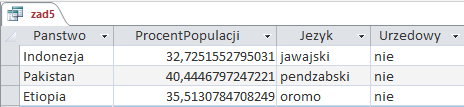
Oto wynik działania kwerendy:
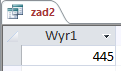
Odpowiedzią jest więc 445 języków.
Zadanie 5 — podpunkt 3

Aby wykonać ten podpunkt znowu potrzebna nam będzie kwerenda pomocnicza, która połączy języki z kontynentami, na których występują. Następnie przy jej użyciu wybierzemy języki, które występują na 4 lub więcej kontynentach.
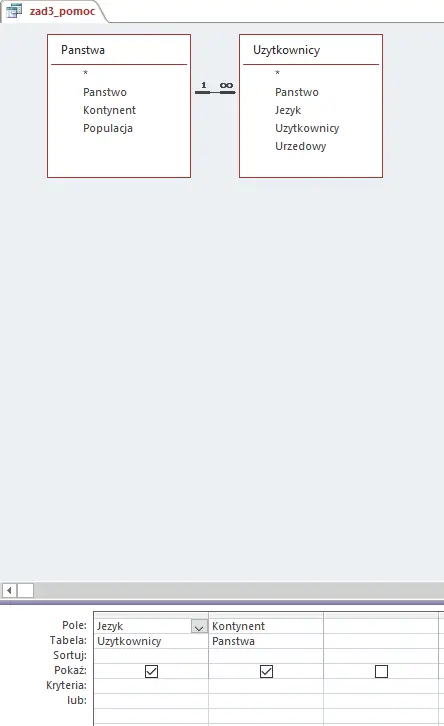

Uwaga: tu również ważne jest dodanie słowa DISTINCT, gdyż dany język może występować kilkukrotnie na danym kontynencie:
Następnie możemy już wybrać interesujące nas języki za pomocą poniższej kwerendy:
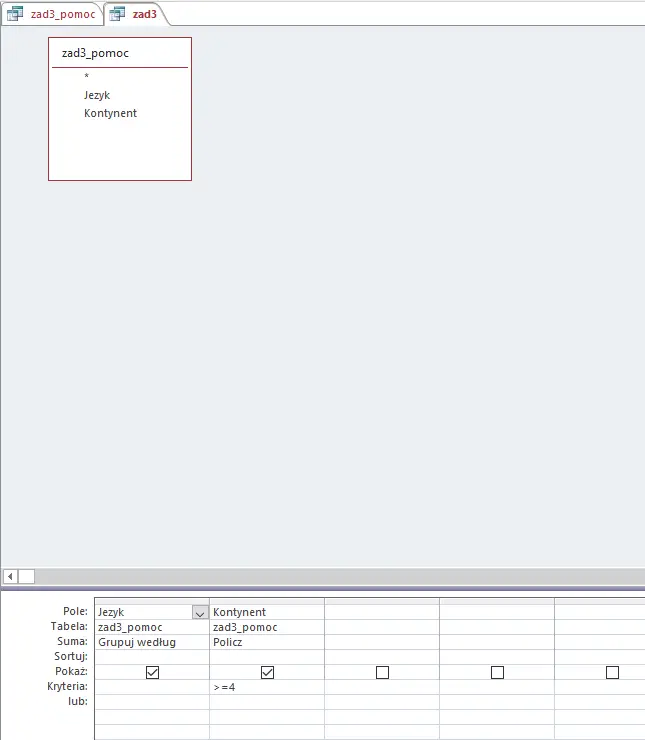
Wynikiem jej działania jest poniższa tabela:
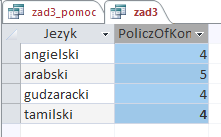
Zadanie 5 — podpunkt 4

W tym podpunkcie skorzystamy z dwóch kwerend – pomocniczej i finalnej, dającej wynik. Pierwsza wybierze język i ilość jego użytkowników dla obu Ameryk i jednocześnie wykluczy języki z rodziny indoeuropejskiej. Druga zliczy ilość użytkowników dla każdego z języków wybranych w poprzedniej kwerendzie, a następnie posortuje je malejąco i wybierze pierwsze sześć języków. Wszystkie kwerendy przedstawiłem poniżej:
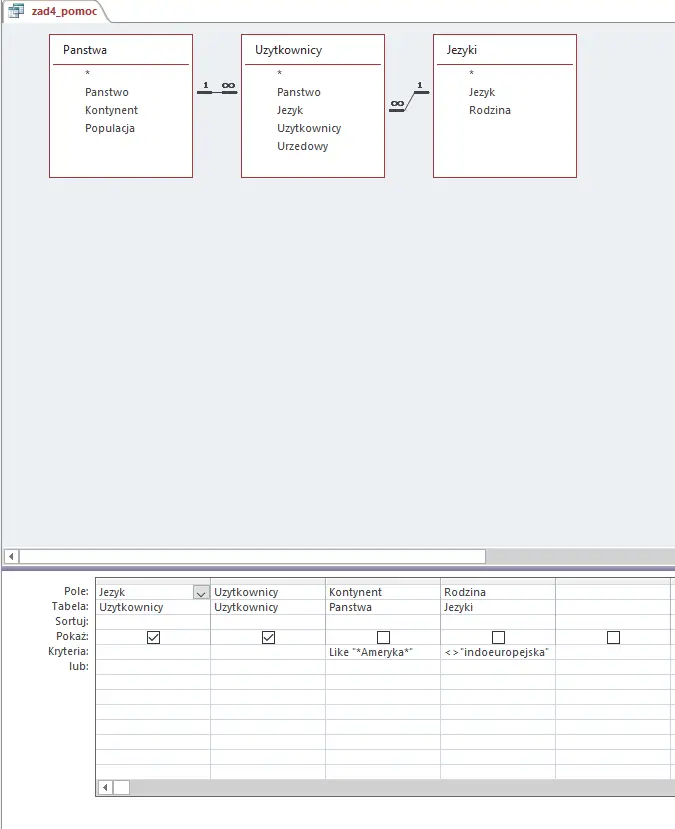
Kwerenda pomocnicza 1.
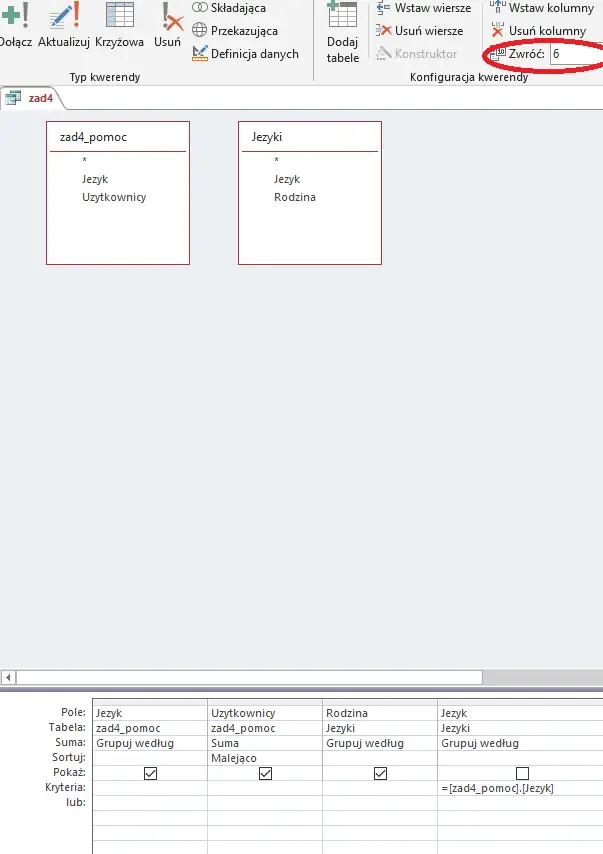
Ostatnia, finalna kwerenda; korzystamy tutaj z „manualnej” relacji poprzez kryteria. Pamiętaj, aby wpisać 6 w polu „Zwróć” w menu „Konfiguracja kwerendy”, a także o sortowaniu malejącym przy konstrukcji kwerendy.
Poniższe zestawienie reprezentuje działanie kwerendy i odpowiedź na ten podpunkt:
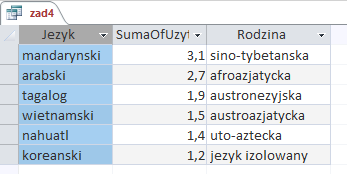
Zadanie 5 — podpunkt 5

Wykorzystamy do rozwiązania prostą kwerendę, która jednocześnie będzie zliczać 30% populacji i porównywać ją do ilości użytkowników języków. Dodatkowo sprawdzi, czy język nie jest urzędowy w danym państwie.
Wynik jej działania załączyłem poniżej jako zrzut:
Matura z informatyki 2020 rozwiązania: zadanie 6 – statek
W ostatnim zadaniu otrzymujemy zbiór informacji na temat pewnego statku. Informacje te jak widzimy na zdjęciu są podzielone na kolumny, więc do pracy z nimi użyjemy programu Microsoft Excel. Import tabeli pokazałem na poniższych zrzutach ekranu:
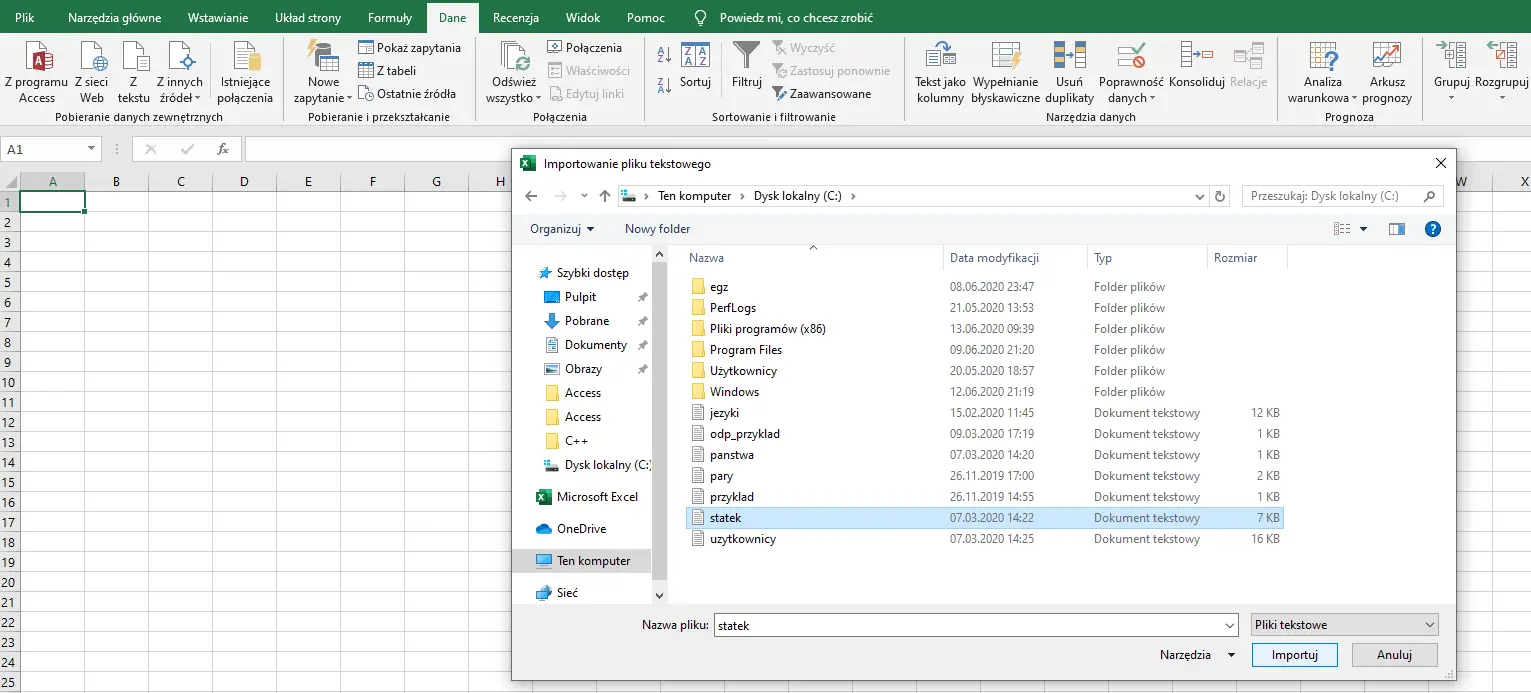
Wybieramy Dane>Z tekstu, a następnie wskazujemy plik statek.txt.
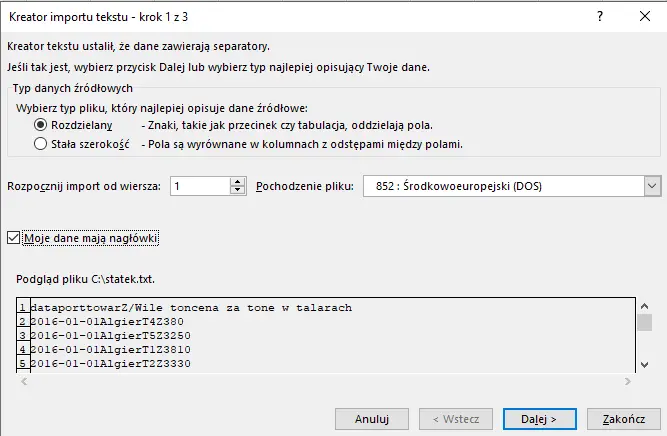
Wybieramy Moje dane mają nagłówki.
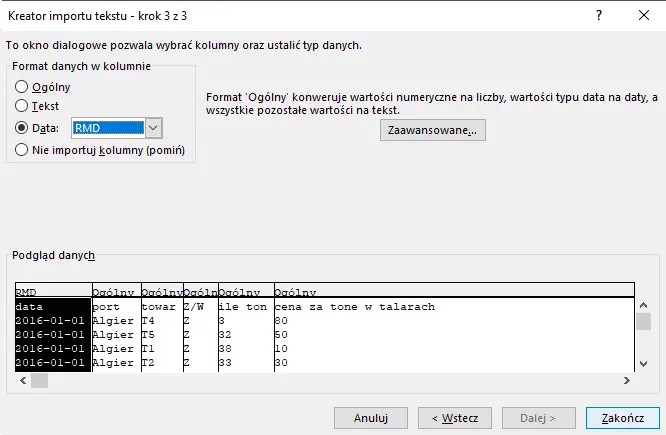
Następnie kolumnie data nadajemy format RMD i klikamy zakończ.
Zaimportowaliśmy dane do arkusza, możemy więc rozpocząć rozwiązywanie podpunktów.
Zadanie 6 — podpunkt 1

Aby wykonać ten podpunkt wykorzystamy sumę częściową. Najpierw sprawdzimy który towar był ładowany najczęściej, a następnie zliczmy ilość ładowanych ton.
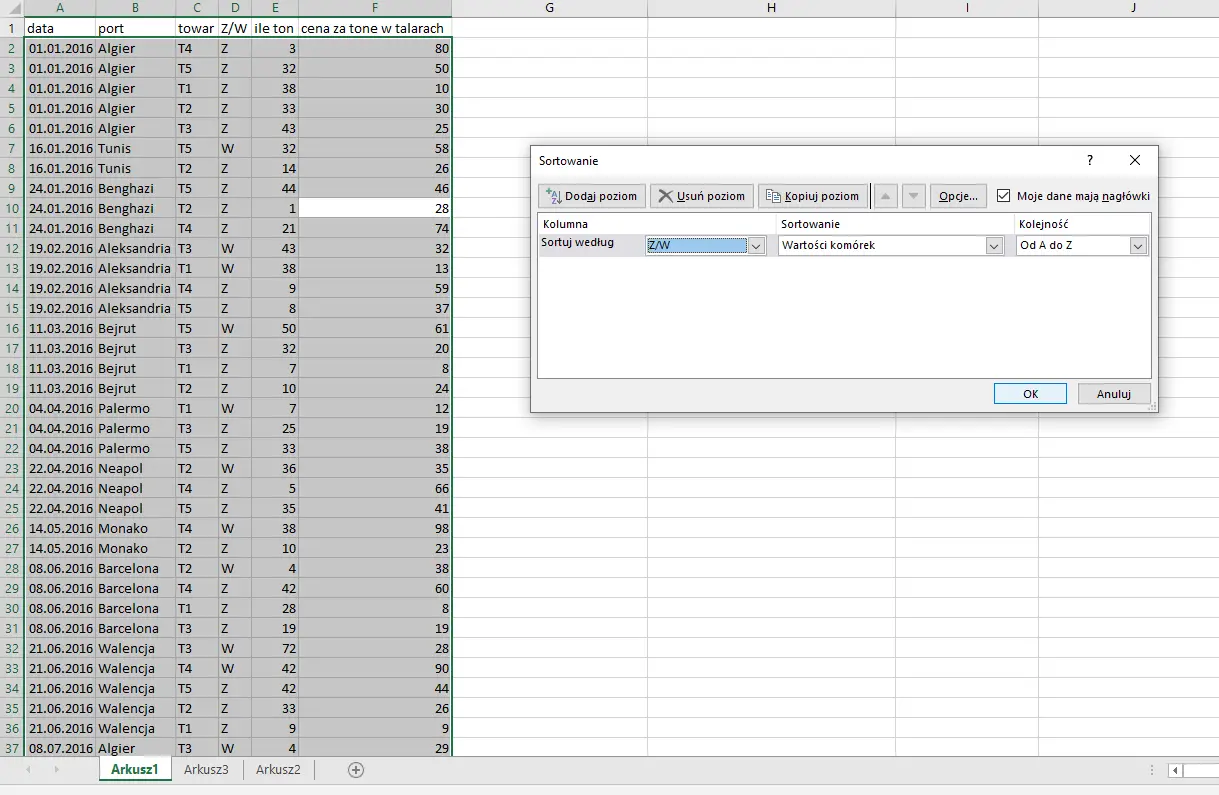
Najpierw musimy posortować dane według załadunku i wyładunku.
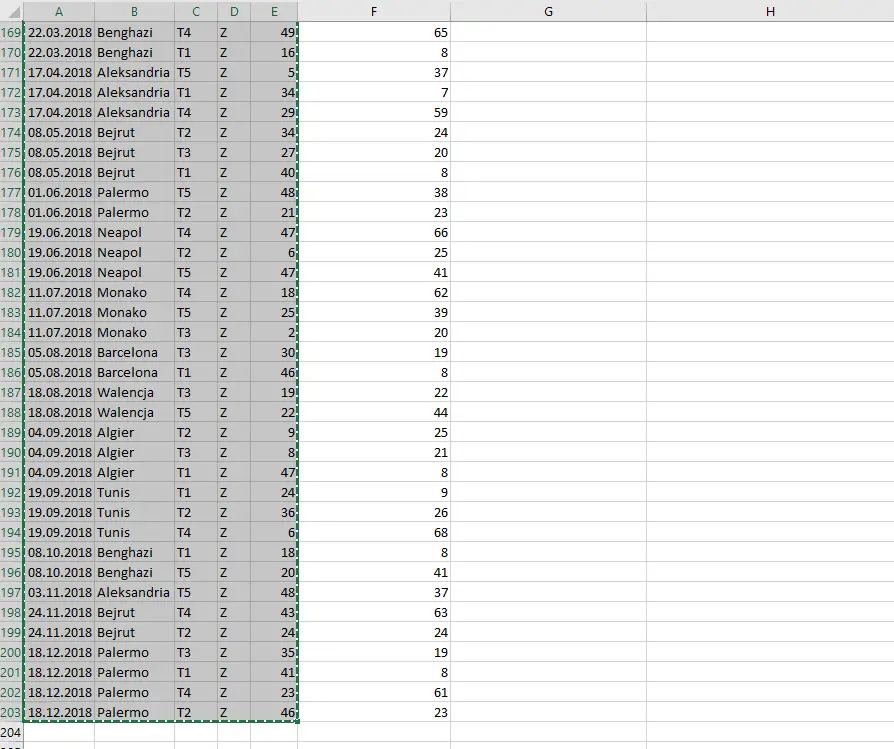
Następnie zaznaczamy i kopiujemy wszystkie załadunki.
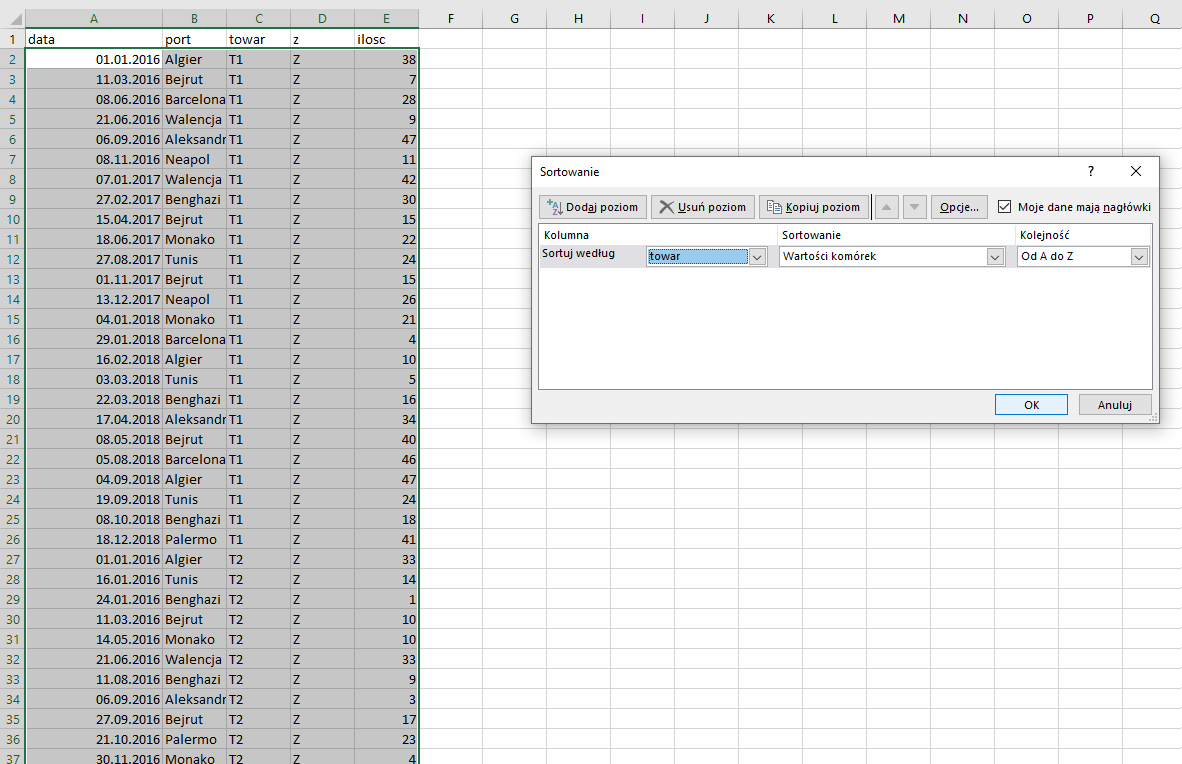
Skopiowane dane wklejamy w nowym arkuszu, a następnie sortujemy według towaru, aby móc zliczyć który był ładowany najczęściej.
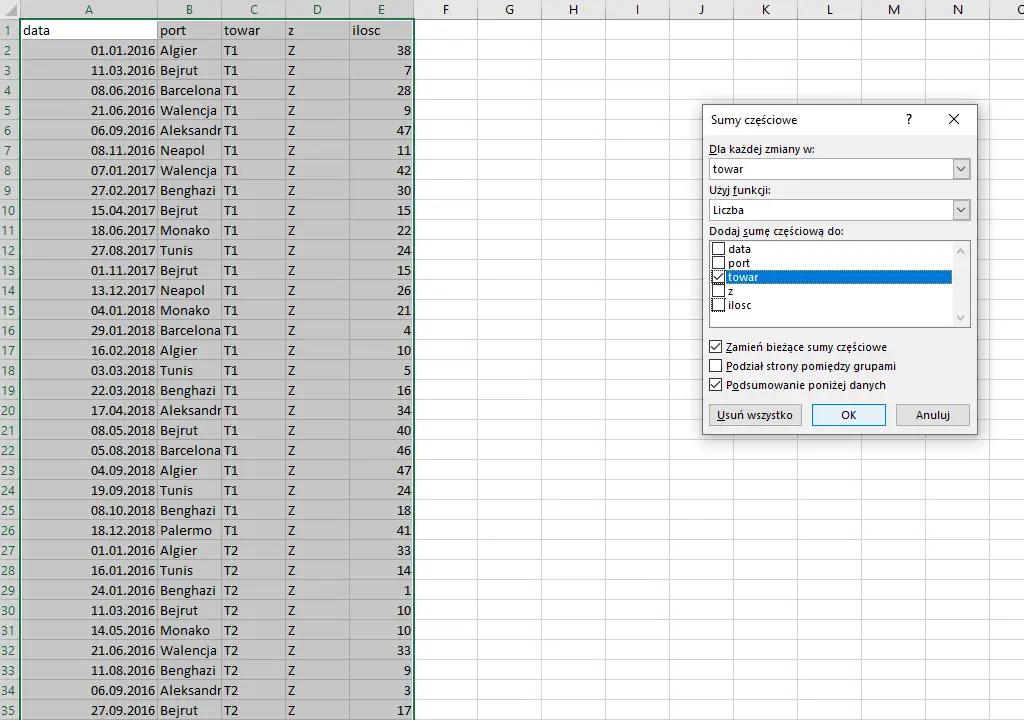
Następnie korzystamy z sumy częściowej tak jak pokazałem na zdjęciu.
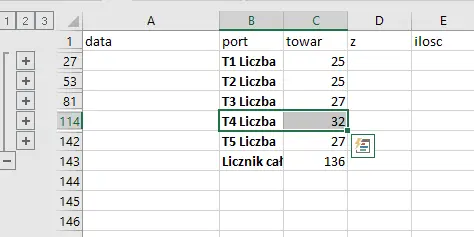
Po wykonaniu sumy częściowej widzimy który towar był ładowany najwięcej razy – T4.
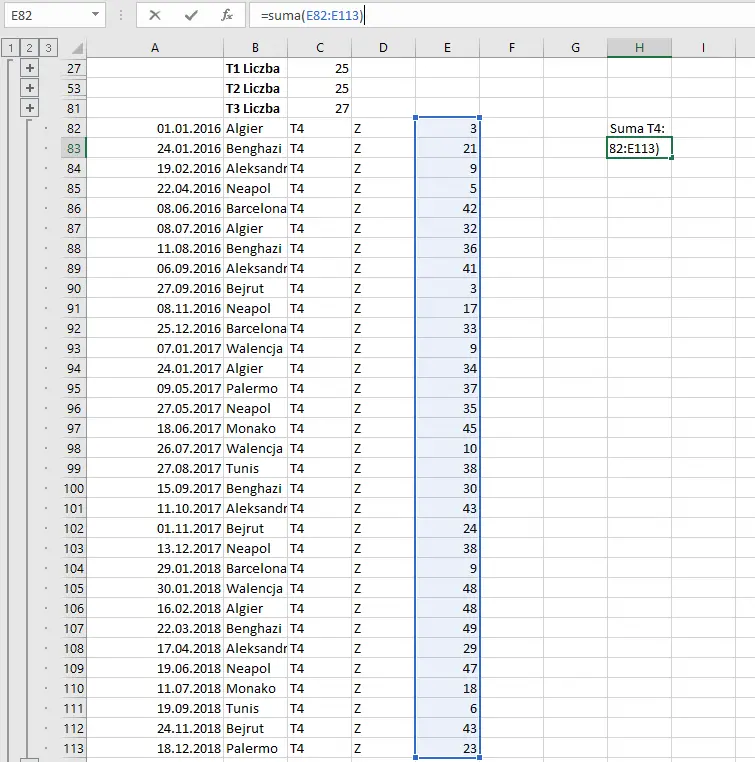
Z lewego menu otwieramy podgrupę, w której są dane na temat towaru T4. Następnie w oddzielnej komórce przy pomocy formuły SUMA zliczamy ilość ton, zaznaczając cały odpowiedni obszar, tak jak na zdjęciu.
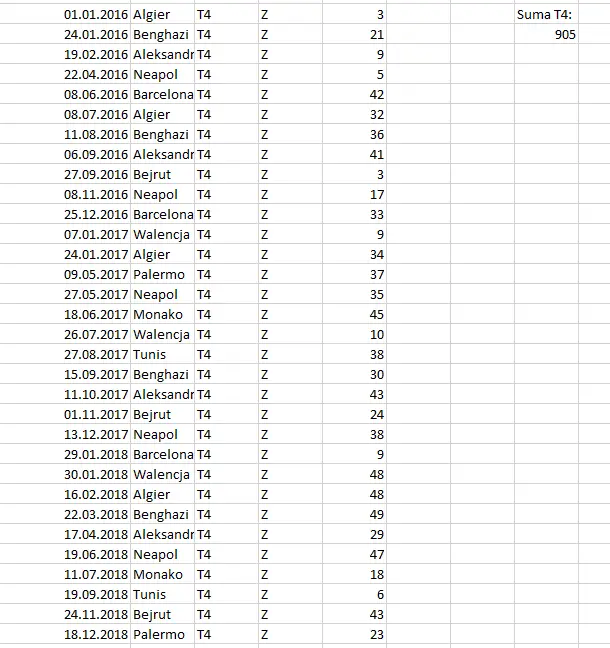
Wynika więc, że najczęściej ładowano towar T4; łączna ilość załadunku tego towaru wynosi 905 ton.
Zadanie 6 — podpunkt 2

Skorzystamy tutaj z formuły JEŻELI, która zwróci 1 gdy spełnione zostaną warunki zadania, a w przeciwnym wypadku 0. Następnie zsumujemy wyniki i otrzymamy ilość takich dni:
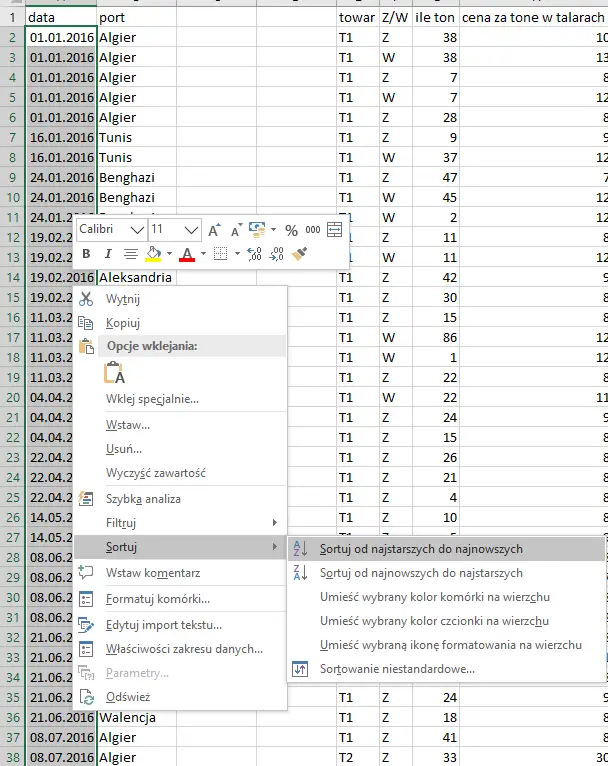
Najpierw musimy posortować dane według daty.
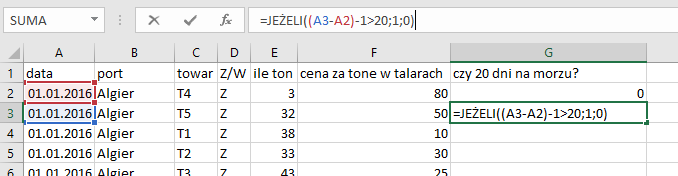
Potem tworzymy formułę sprawdzającą warunek (zwróć uwagę na -1 przy warunku — wynika to z faktu, który przestawiono w treści przykładu). Podaną formułę „rozciągamy” na całą kolumnę, poprzez dwukrotne kliknięcie małego kwadracika w prawym dolnym rogu.

Następnie zliczamy każdy 20 dniowy rejs za pomocą SUMA.

Oto odpowiedź na pytanie z tego podpunktu.
Zadanie 6 — podpunkt 3

Dosyć skomplikowany podpunkt, w którym zliczymy łączną ilość załadunku i wyładunku dla każdego towaru aż do wskazanych w poleceniu dni, a następnie podamy którego było najwięcej/najmniej. Uwaga: dane muszą być znowu posortowane według daty!
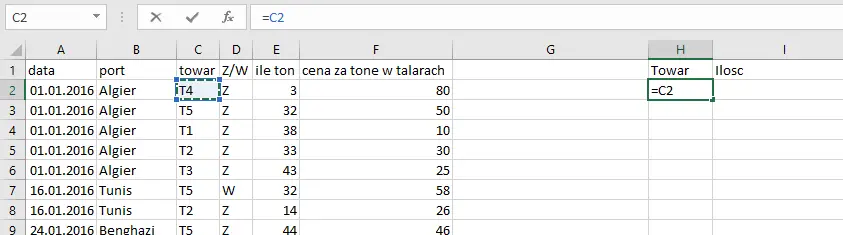
Tworzymy dwie nowe kolumny o formułach podanych na zdjęciach.

Obie formuły ponownie rozciągamy na długość całej kolumny.
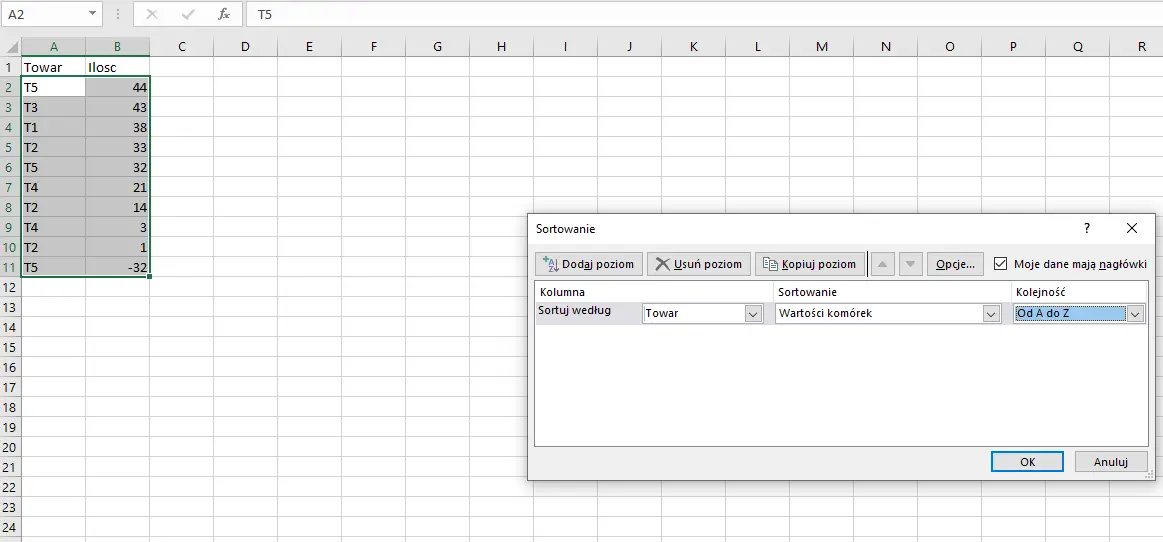
Tak powstałe kolumny kopiujemy w DO DNIA 2016-01-02!, a następnie wklejamy w nowym arkuszu (uwaga: wybierz Wklej>Wklej tylko wartości). Następnie sortujemy je według Towaru.
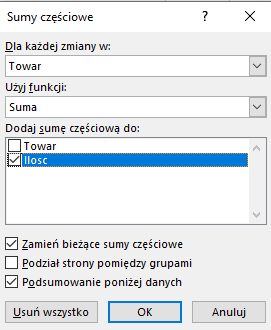
Korzystamy z sumy częściowej tak, jak pokazano na zdjęciu.
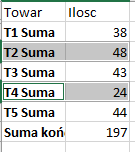
Po wejściu w drugą zakładkę menu z lewej strony, widzimy łączną ilość ton dla każdego towaru do dnia 2016-02-01.
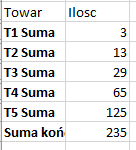
Powyższe kroki powtarzamy, z tym że uwzględniamy wszystkie rejsy do dnia 2018-08-01. Wyniki tych kroków powinny być takie, jak na załączonym zdjęciu.

Na koniec zbieramy dane i zapisujemy w komórkach, aby odpowiedź była czytelna.
Zadanie 6 — podpunkt 4

Skorzystamy tutaj z dosyć skomplikowanej formuły SUMA.ILOCZYNÓW, która pozwoli na znalezienie zbioru spełniającego kilka warunków:
Sortujemy dane według towaru.
Kopiujemy interesujące nas dane do nowego arkusza.
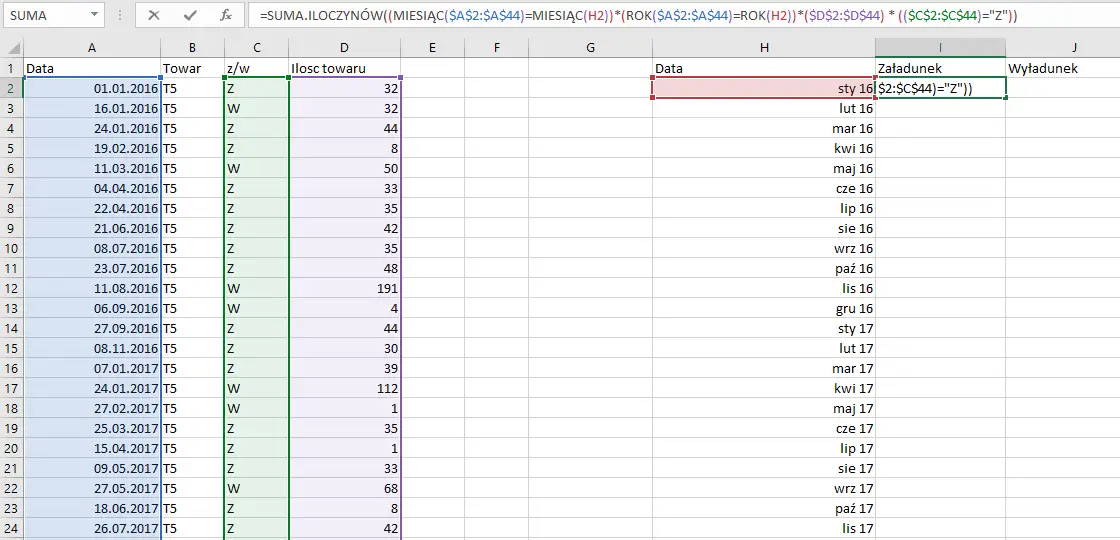
Następnie tworzymy kolumnę Data, w której umieścimy wszystkie miesiące z okresu podanego w poleceniu. Zwróć uwagę, że zmieniłem w nich format daty (możesz to zrobić z poziomu zakładki Narzędzia główne). Aby nie wpisywać osobno miesięcy, możesz również wpisać kolejno pierwsze trzy, zaznaczyć je i przeciągnąć kwadracikiem w dół, aż do uzyskania pożądanego miesiąca. Następnie obok tworzymy kolumny Załadunek oraz Wyładunek. W kolumnie załadunek wpisujemy powyższą formułę; sprawdza ona po pierwsze czy w danym zakresie znajduje się określony komórką obok miesiąc i rok, a następnie czy jest to załadunek (Z). Zauważ, że w większości komórek użyłem stałych odwołań przy użyciu znaczku dolara $, a to dlatego, bo gdy teraz zastosujesz tą formułę dla całej kolumny, to zaznaczone dane również „uciekałyby” w dół. Zastosuj więc tą formułę dla całej kolumny.

Zastosuj ją też dla drugiej kolumny (tylko pamiętaj, aby w warunku zmienić =”Z” na =”W”).
Z tak utworzonych kolumn możemy już utworzyć wykres.
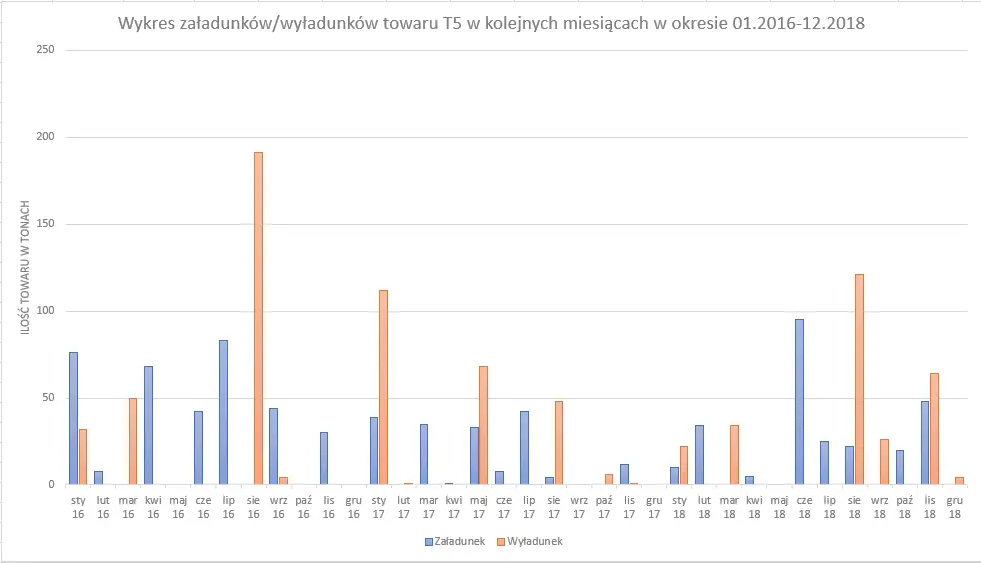
Pamiętaj, aby zachować czytelność wykresu i danych przez niego reprezentowanych.
Zadanie 6 — podpunkt 5

W nowej kolumnie policzmy zatem ile kapitan zapłacił/wydał, a następnie dodamy tą liczbę do jego kasy do jego kasy. Przy użyciu funkcji MAX, oraz dodatkowo dla wygody INDEKS i PODAJ.POZYCJĘ znajdziemy również dzień, w którym miał najwięcej pieniędzy:
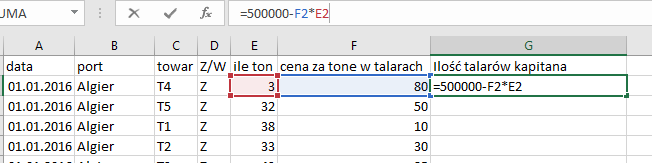
Liczymy ile pieniędzy miał po pierwszej transakcji.
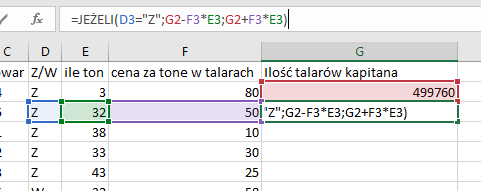
Następnie tworzymy formułę, która będzie odpowiednio dodawać lub odejmować wyliczoną ilość talarów od kasy kapitana zależnie od tego, czy jest to wyładunek, czy załadunek. Formułę oczywiście należy zastosować na całą długość kolumny.

Następnie tworzymy komórkę, która poda stan kasy na ostatni dzień, gdy statek był w porcie.
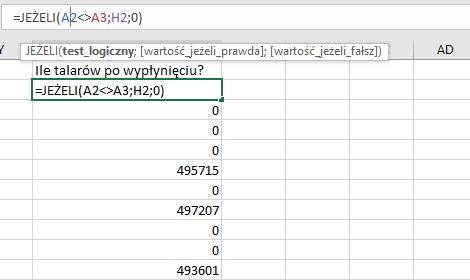
Musimy teraz utworzyć kolumnę, która sprawdzi stan kasy na sam koniec dnia (jak wiemy z zadania, to właśnie wtedy statek opuszczał port, a o to nas pytają w zadaniu)
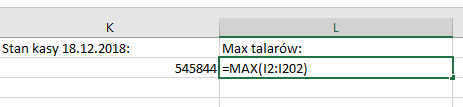
Sprawdzamy teraz z utworzonej kolumny ile miał najwięcej pieniędzy, a następnie odszukujemy dzień, w którym to miało miejsce.

Pełna odpowiedź na podpunkt a).
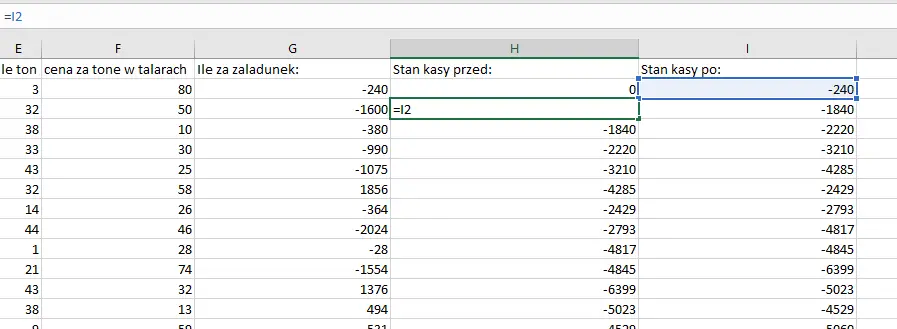
Teraz sprawdzimy ile pieniędzy musiałby posiadać kapitan, aby mieć za co za każdym razem opłacić transakcję. Musimy tutaj uwzględnić jego zarobki, więc skorzystamy z kolumny utworzonej w poprzednim zadaniu, a następnie dodamy dwie kolumny, które podsumują stan jego kasy przed i po transakcji:

Następnie dodajemy pod nimi komórki, które będą aktualizować stan kasy zależnie od wydatków/zarobków z danego dnia (oczywiście formułę „rozciągamy” na całą kolumnę):
Kolejnym krokiem będzie znalezienie najniższej wartości w nowo utworzonej kolumnie – liczba przeciwna do tej wartości będzie minimalną ilością pieniędzy potrzebnej do uiszczenia wszystkich transakcji:
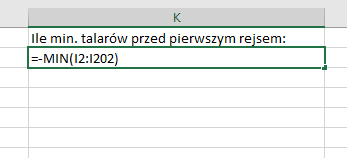
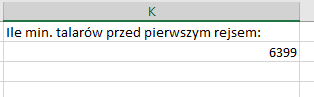
Otrzymujemy odpowiedź na podpunkt b).
Podsumowanie
Jak sami widziecie tegoroczny arkusz nie należał do najłatwiejszych. Niemniej mam nadzieję, że te rozwiązania do matury z informatyki 2020 pomogą wam lepiej zrozumieć jej specyfikę. Powodzenia w nauce!


