
Zaczyna się ulubiony dzień każdego z nas, a wraz z nim pojawia się kolejna część „Piątku z sortowaniem”. Tym razem weźmiemy pod lupę sortowanie binarne (binary sort), które jest sprawą odrobinę bardziej skomplikowaną, od wcześniej prezentowanych algorytmów. Nie bójcie się jednak. Razem przeanalizujemy jego działanie krok po kroku.
Poszukiwania
Zanim przejdziemy do algorytmu sortowania, musimy zadać sobie ważne pytanie. Jak ma się wyszukiwanie binarne do algorytmu sortowania binarnego?
Sortowanie binarne, jest tak naprawdę modyfikacją sortowania przez wstawianie. Jeśli jeszcze go nie znacie, jego opis oraz implementacje znajdziecie w poprzedniej części „Piątku z sortowaniem”. Algorytm ten został ulepszony przez dodanie wyszukiwania binarnego, więc ujmując rzecz precyzyjnie, sortowanie binarne, to tak naprawdę sortowanie przez wstawianie z wyszukiwaniem binarnym (binary insertion sort). Nic dziwnego, że potocznie przyjęto krótszą nazwę 😉.
By więc w pełni zrozumieć sortowanie binarne, najpierw musimy poznać jak dokładnie działa wyszukiwanie binarne.

Dziel i zwyciężaj
Algorytm wyszukiwania binarnego służy do wyszukiwania elementów w posortowanym zbiorze liczbowym. Opiera się on na, bardzo dobrze znanej w programowaniu, zasadzie „dziel i zwyciężaj”. Algorytm ten dzieli tablice na mniejsze części, aż do momentu znalezienia szukanego elementu. Omówmy jego działanie krok po kroku.
1.Na początku wyznaczamy środkową pozycję tablicy, korzystając z wzoru:
sr = (l + p)/2
gdzie:
- sr – indeks środka tablicy
- l – indeks lewego krańca tablicy
- p – indeks prawego krańca tablicy
Jeśli tablica ma parzystą liczbę elementów, to wynik dzielenia zaokrąglamy w dół. Zakładamy, że do obliczeń używamy liczb całkowitych (int), w przypadku których, reszta z dzielenia jest zwyczajnie odrzucana.
2.Gdy nasze zmienne są już wyznaczone, sprawdzamy czy liczba, kryjąca się pod indeksem sr, jest szukaną liczbą. Jeśli nie, sprawdzamy czy szukany element jest większy, czy mniejszy od elementu pod indeksem sr. Mamy wtedy dwa możliwe scenariusze:
- Element szukany jest większy – Jako, iż jest to posortowany zbiór, logicznym jest, że nasz element powinien znajdować się na prawo od środkowego indeksu, wśród większych liczb. Wyznaczamy więc podtablicę, odrzucając wszystkie elementy znajdujące się przed indeksem sr+1. Dokonujemy tego, przez zmianę wartości lewego indeksu tablicy:
l = sr + 1
- Element szukany jest mniejszy – Analogicznie do powyższej sytuacji, wyznaczamy podtablicę, odrzucając wszystkie elementy znajdujące się na prawo od indeksu sr-1:
p = sr -1
Ponownie wykonujemy wszystkie kroki, zaczynając od wyznaczenia środkowego indeksu sr. Robimy to, aż do momentu gdy natrafimy na szukany element.
Co jeśli szukanego elementu nie ma w zbiorze? Algorytm ten jest również przygotowany na tą możliwość. Przed każdym wyznaczeniem nowego indeksu sr, wystarczy sprawdzić czy l>r. Jeśli tak, oznacza to, że naszego elementu nie ma w zbiorze.
By zobrazować sobie działanie algorytmu spójrzcie na poniższą animację:

Zauważcie, że w powyższym przypadku, korzystając z wyszukiwania liniowego (przechodzenia przez wszystkie elementy po kolei), znalezienie indeksu szukanego elementu, zajęłoby nam aż pięć kroków. Korzystając z wyszukiwania binarnego, znaleźliśmy element w trzech. Łatwo wyobrazić sobie ile kroków „zaoszczędzilibyśmy”, w przypadku przeszukiwania, nie siedmioelementowego zbioru, lecz tablicy z siedmioma tysiącami elementów.
Znając już w pełni zasadę działa wyszukiwania binarnego, możemy przejść do sortowania binarnego.
Ulepszenie
Sortowanie binarne nie różni się znacząco, od omawianego w poprzedniej części, sortowania przez wstawianie. Nic dziwnego, skoro jest to jego usprawniona wersja. Tak samo jak w podstawowej wersji algorytmu, wybieramy kolejne elementy i wstawiamy je w miejsca docelowe. Jedyną różnicą jest fakt, że do wyszukania pozycji, w której ma znaleźć się wybrany przez nas element, skorzystamy z wyszukiwania binarnego.
Jak jednak wyznaczyć warunek końca algorytmu wyszukiwania binarnego, skoro wcześniej szukaliśmy konkretnego elementu, a nie dogodnej pozycji? Otóż jego działanie wyglądać będzie następująco.
Wybierając element, który mamy wstawić w miejsce docelowe, wyznaczamy środek już uporządkowanego zbioru liczb, gdzie indeksy l i r, są jego krańcami. Następnie porównujemy wybrany element, z elementem pod środkowym indeksem. Jeśli jest mniejszy – odrzucamy całą prawą część podtablicy. Jeśli będzie większy – odrzucamy lewą.
Są dwa główne warunki końca algorytmu wyszukiwania pozycji:
- Wartość indeksów l, r i sr będą sobie równe – Jeśli element pod indeksem sr, będzie większy od elementu wstawianego, szukana pozycja to sr-1, w przypadku kiedy będzie mniejszy, szukaną pozycją będzie sr+1 (można także skorzystać z notacji l+1).
- Wartość indeksu l, jest większa od r – należy sprawdzić czy wartość elementu znajdującego się pod indeksem l, jest większa od wstawianego elementu. Jeśli tak, wstawiamy nasz elementu na l+1, jeśli nie, na pozycję wskazywaną przez indeks l.
Jeśli sortujemy tablicę, w której wartości poszczególnych elementów powtarzają się, podczas porównywania elementów dodajemy jeden prosty warunek. Jeżeli wartość elementu pod indeksem sr, będzie równa wartości wstawianego elementu, to nowa pozycja tego elementu wynosić będzie sr+1, kończąc przy tym wyszukiwanie.
Trochę praktyki
Algorytmy najlepiej poznawać na przykładach, tak wykonajmy kilka pierwszych kroków sortowania binarnego.
Weźmy zbiór [15, 63, 1, 81, 9]. Zaczynamy od wstawienia elementu o wartości 63, na miejsce docelowe. Wyznaczamy środek posortowanego już zbioru – w tym przypadku zbioru zawierającego jedynie element 15, a co za tym idzie jego środek znajduje się pod indeksem 0. Indeksy l,r i sr, są sobie równe, więc mamy element zbioru uporządkowanego, mający wartość najbliższą elementowi wstawianemu. Jako, że 63 jest większe od 15, jego docelowe miejsce znajduje się pod indeksem równym 1, czyli element ten nie zmienia pozycji.
Przechodzimy do kolejnego kroku. Tym razem wykonujemy porównanie dla elementu o wartości 1. Wyznaczamy wartość indeksu sr, dla l = 0 i r=1. Wartość indeksu środkowego ponownie wynosi 0. Wykonujemy porównanie. 1 jest mniejsze od 15. Jako, że indeksy l i r nie są równe, musimy wyznaczyć nową podtablicę, gdzie r = sr – 1. W kolejnym kroku wyszukiwania zauważamy, że wartość indeksu l jest większa od r (l = 0, r = -1), oznacza to, że trafiliśmy na jeden z warunków zakończenia algorytmu wyszukiwania. By otrzymać miejsce na które mamy wstawić nasz element, musimy jedynie sprawdzić, czy element wstawiany jest większy, od elementu pod indeksem l. Nie jest tak (15 > 1), więc element o wartości 1, wstawiony zostaje na pozycję 0, a pozostałe elementy przesunięte w głąb tablicy.
Na wykonanie pojedynczych kroków algorytmu, potrzebowaliśmy wykonać dość dużo porównań. Aby więc ułatwić zrozumienie algorytmu, spójrzmy na animację obrazującą sortowanie binarne całego powyższego zbioru:
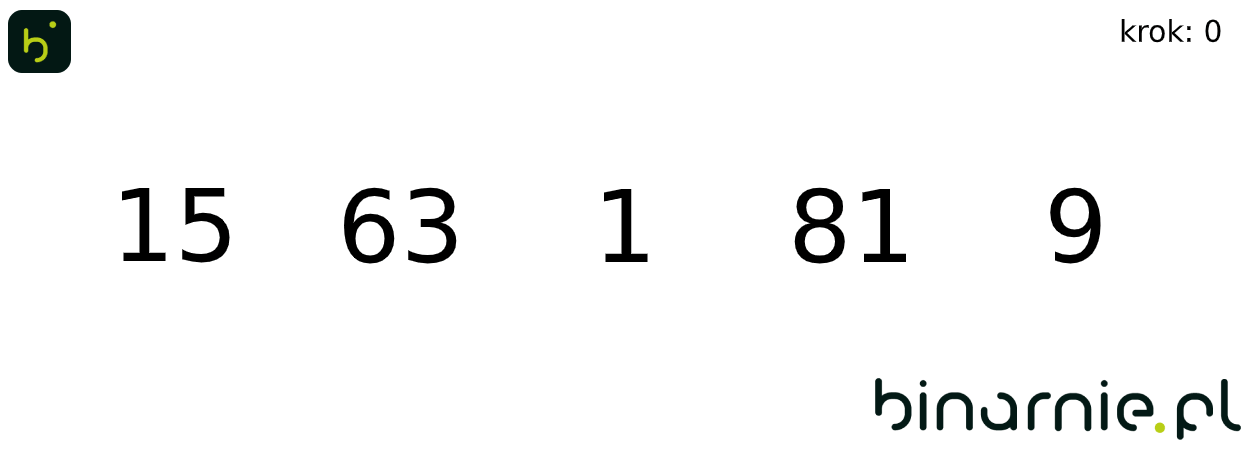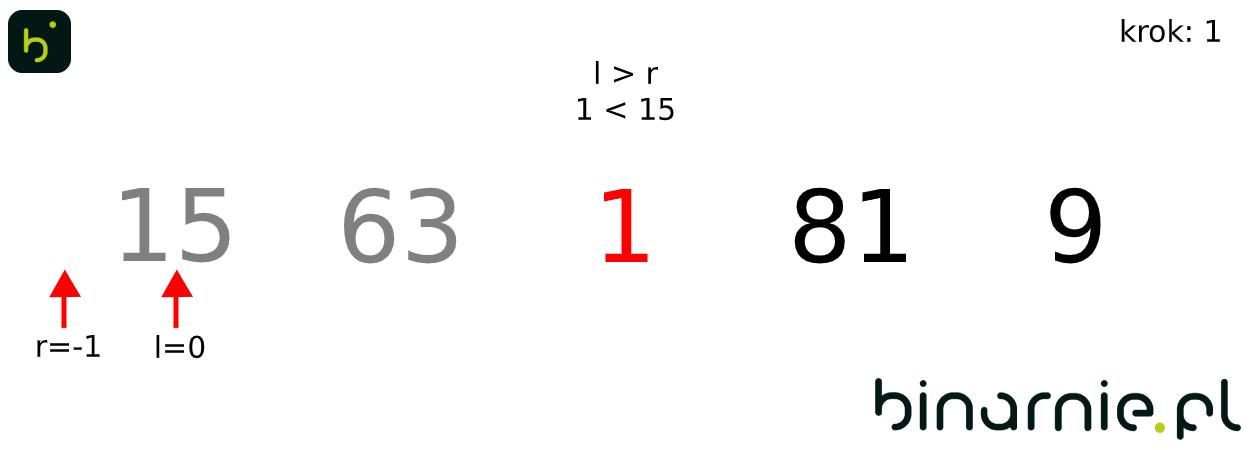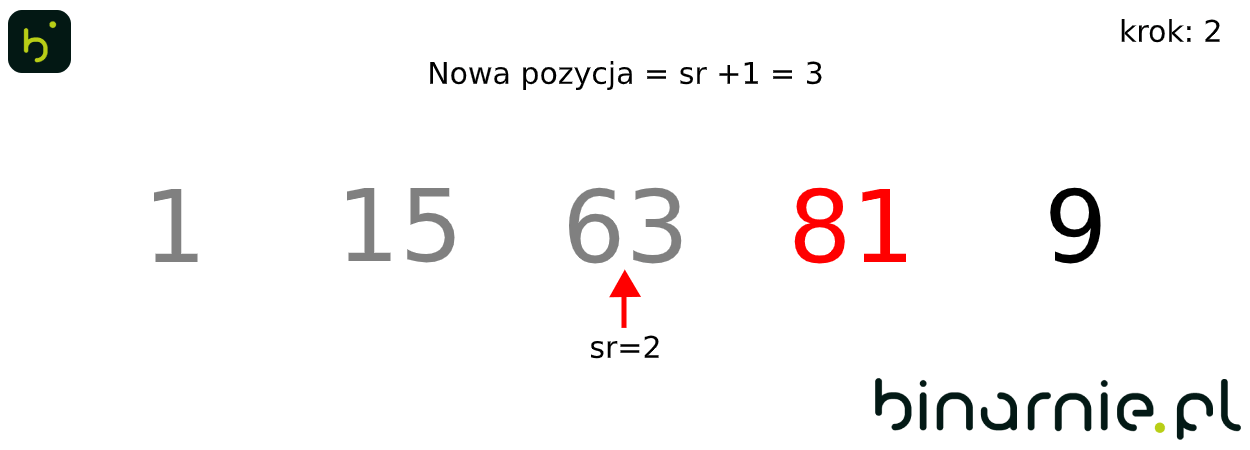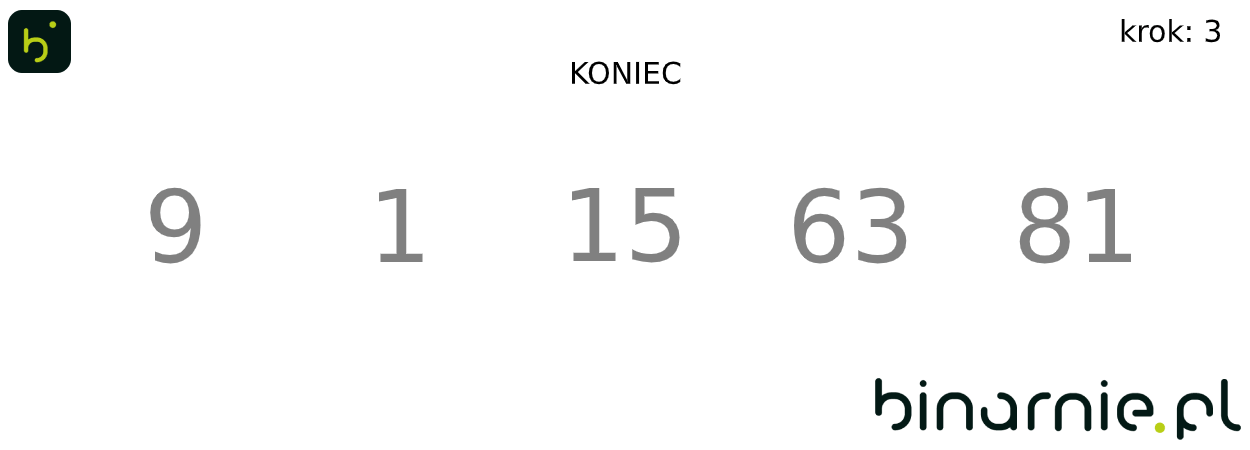
Właściwości
Optymistyczna złożoność sortowania binarnego wynosi O(nlogn), więc teoretycznie, powinien być on szybszy od zwykłego sortowania przez wstawianie. Zauważcie jednak ile porównań musieliśmy wykonać, już w drugim kroku tego algorytmu, gdzie przy przeszukiwaniu liniowym, byłoby ich znacznie mniej.
Puenta jest więc następująca – owszem sortowanie binarne jest szybsze od sortowania przez wstawianie, ale jedynie dla większych zbiorów. W przypadku małych zbiorów, jak ten z przykładu powyżej, jest on wolniejszy, lub ledwo porównywalnie szybszy.
Sortowanie binarne – implementacje
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 |
//program do sortowania n-elementowej tablicy //przy pomocy algorytmu sortowania binarnego //Jan Żwirek #include <iostream> using namespace std; void printTab(int *tab, int n); //Funkcja służąca do binarnego wyszukiwania pozycji int binaryPositionSearch(int *tab, int selectedElement, int l, int r) { cout << "\tPodtablica o indeksach l=" << l << " i r=" << r << endl; //W przypadku gdy natrafimy na jeden z warunków //zakonczenia algorytmu, zwracamy pozycje if (l >= r) { if (selectedElement >= tab[l]) { cout << "\tZNALEZIENIE NOWEJ POZYCJI = " << l + 1 << endl << endl; return l + 1; } else { cout << "\tZNALEZIENIE NOWEJ POZYCJI = " << l << endl << endl; return l; } } int sr = (l + r) / 2; //Warunek zakończenia wyszukiwania, dla elemetów o takiej samej wartości if (tab[sr] == selectedElement) { cout << "\tZNALEZIENIE NOWEJ POZYCJI = " << l + 1 << endl << endl; return l + 1; } //W przypadku gdy nie natrafiliśmy na warunek końcowy //wywołujemy rekurencyjnie funkcje wyszukiwania binarnego, //podając w argumentach indeks odpowiedniej połowy tablicy if (selectedElement > tab[sr]) { return binaryPositionSearch(tab, selectedElement, sr + 1, r); } else { return binaryPositionSearch(tab, selectedElement, l, sr - 1); } } void binarySort(int *tab, int n) { for (int x = 1; x < n; x++) { //Wybieramy element który chcemy porównywać int selectedElement = tab[x]; int y = x - 1; //Rozpoczynamy przesuwanie elementów szukając miesjca docelowego //dla wybranego przez nas elementu cout << "Rozpoczecie wyszukiwania binarnego nowej pozycji " << endl; cout << "dla elementu o wartosci = " << selectedElement << endl; int pozycja = binaryPositionSearch(tab, selectedElement, 0, y); for (y = x - 1; y >= pozycja; y--) { tab[y + 1] = tab[y]; } if (x != y + 1) { cout << "\nKrok " << x - 1 << ": Przenoszenie elementu o wartosci " << selectedElement; cout << " z pozycji " << x << " na pozycje " << pozycja << endl; } else { cout << "\nKrok " << x - 1 << ": Element o wartosci " << selectedElement; cout << " pozostaje na pozycji " << x << endl; } tab[pozycja] = selectedElement; printTab(tab, n); } } int main() { int n; cout << "Wprowadz liczbe elementow tablicy: "; cin >> n; //Dynamiczne tworzenie tablicy int *tab = new int[n]; cout << "\nWprowadz " << n << " liczb do posortowania" << endl; cout << "Zatwierdz kazda z nich klawiszem Enter:" << endl; for (int x = 0; x < n; x++) { cin >> tab[x]; } cout << endl << "Tablica przed posortowaniem:" << endl; printTab(tab, n); cout << endl << "Rozpoczecie sortowania" << endl; binarySort(tab, n); cout << endl << "Oto tablica po sortowaniu:" << endl; printTab(tab, n); delete[] tab; system("pause"); return 0; } void printTab(int *tab, int n) { cout << endl << "\t| "; for (int x = 0; x < n; x++) { cout << tab[x] << " | "; } cout << endl << endl; } |
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 |
package matura; import java.util.Scanner; public class Main { private static void printArray(int[] tab) { System.out.println(); for(int i = 0; i < tab.length; i++) { System.out.print(tab[i] + " | "); } System.out.println(); } //Funkcja służąca do binarnego wyszukiwania pozycji private static int binaryPositionSearch(int[] tab, int selectedElement, int l, int r) { System.out.println("Podtablica o indeksach l=" + l + " i r=" + r); //W przypadku gdy natrafimy na jeden z warunków //zakonczenia algorytmu, zwracamy pozycje if (l >= r) { if (selectedElement >= tab[l]) { System.out.println("ZNALEZIENIE NOWEJ POZYCJI = " + (l + 1)); System.out.println(); return l + 1; } else { System.out.println("ZNALEZIENIE NOWEJ POZYCJI = " + l); return l; } } int sr = (l + r) / 2; //Warunek zakończenia wyszukiwania, dla elemetów o takiej samej wartości if (tab[sr] == selectedElement) { System.out.println("ZNALEZIENIE NOWEJ POZYCJI = " + ( l + 1) ); System.out.println(); return l + 1; } //W przypadku gdy nie natrafiliśmy na warunek końcowy //wywołujemy rekurencyjnie funkcje wyszukiwania binarnego, //podając w argumentach indeks odpowiedniej połowy tablicy if (selectedElement > tab[sr]) { return binaryPositionSearch(tab, selectedElement, sr + 1, r); } else { return binaryPositionSearch(tab, selectedElement, l, sr - 1); } } private static void binarySort(int[] tab) { for (int x = 1; x < tab.length; x++) { //Wybieramy element który chcemy porównywać int selectedElement = tab[x]; int y = x - 1; //Rozpoczynamy przesuwanie elementów szukając miesjca docelowego //dla wybranego przez nas elementu System.out.println("Rozpoczecie wyszukiwania binarnego nowej pozycji "); System.out.println("dla elementu o wartosci = " + selectedElement); int pozycja = binaryPositionSearch(tab, selectedElement, 0, y); for (y = x - 1; y >= pozycja; y--) { tab[y + 1] = tab[y]; } if (x != y + 1) { System.out.println("Krok " + (x - 1) + ": Przenoszenie elementu o wartosci " + selectedElement + " z pozycji " + x + " na pozycje " + pozycja); } else { System.out.println("Krok " + (x - 1) + ": Element o wartosci " + selectedElement + "pozostaje na pozycji " + x); } tab[pozycja] = selectedElement; printArray(tab); } } public static void main(String[] args){ Scanner sc = new Scanner(System.in); //inicjalizujemy Scanner - obiekt pozwalajacy na wczytywanie zmiennych od uzytkownika System.out.println("Wprowadz liczbe elementow tablicy: "); int n = sc.nextInt(); int[] arr = new int[n]; for(int i = 0; i < n; i++) { System.out.println("Podaj element nr." + i + ": "); arr[i]= sc.nextInt(); //wczytujemy kolejne elementy tablicy } System.out.println("Oto wprowadzona tablica:"); printArray(arr); binarySort(arr); System.out.println("Oto wprowadzona tablica po przesortowaniu:"); printArray(arr); sc.close(); //zwalniamy zasoby } } |
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
def wypisz(tab): # tworzymy metode do wypiswania zawartosci naszej tablicy for el in tab: print(el, end=" | ") def binarySearch(tab, element, l, r): print("Podtablica o indeksach l=", l, " i r=", r) if l >= r: # warunek zakanczajacy rekurencje if element >= tab[l]: # jezeli wybrany element jest wiekszy lub rowny lewemu krancowi print("ZNALEZIENIE NOWEJ POZYCJI = ", (l + 1)) # zwroc pozycje o jeden wieksza return l + 1 else: print("ZNALEZIENIE NOWEJ POZYCJI = ", l) # w przeciwnym wypadku zwroc ta pozycje return l sr = int((l + r) / 2) # wyznaczamy srodek if tab[sr] == element: # warunek zakanczajacy rekurencje, w przypadku gdy znajdziemy element rowny print("ZNALEZIENIE NOWEJ POZYCJI = ", (l + 1)) # zwroc pozycje o jeden wieksza return l + 1 if tab[sr] < element: return binarySearch(tab, element, sr + 1, r) else: return binarySearch(tab, element, l, sr - 1) def sortuj_bin(tab, n): for x in range(1, n): # iterujemy poprzez wszsytkei elementy tablicy, poza pierwszym element = tab[x] y = x - 1 print("Rozpoczecie wyszukiwania binarnego nowej pozycji ") print("dla elementu o wartosci = ", element) pos = binarySearch(tab, element, 0, y) while y >= pos: tab[y + 1] = tab[y] y -= 1 if x != y + 1: print("Krok ", (x - 1), ": Przenoszenie elementu o wartosci ", element, " z pozycji ", x, " na pozycje ", pos) else: print("Krok ", (x - 1), ": Element o wartosci ", element, "pozostaje na pozycji ", x) tab[pos] = element wypisz(tab) print("Podaj ilosc elementow tablicy:") a = int(input()) tablica = [] for i in range(a): print("Podaj element nr. ", (i + 1)) tablica.append(int(input())) print("Oto twoja tablica:") wypisz(tablica) sortuj_bin(tablica, a) print("Oto twoja tablica po sortowaniu:") wypisz(tablica) |
Podsumowanie
Rozgryzanie sortownia binarnego właśnie za nami. Mimo tego, że był to,
w porównaniu do poprzednich, nieco cięższy kawałek algorytmu, dobrnęliście ze mną do końca. Jeśli jesteście ciekawi działania kolejnych algorytmów, serdecznie zapraszam was za tydzień, na kolejną część „Piątku z sortowaniem” 😊.



Awksi
says:Witam
Algorytm (przynajmniej w pythonie) ma błąd ponieważ dla listy [0, 1, 2, 2, 2, 2] zwraca [0, 2, 1, 2, 2, 2]
Wydaje mi się że jest to kwestia 18 linijki w której powinno być return sr + 1